[Data Analysis] SQL Recipe for Data Analysis Tutorial #3 - Manipulating multiple values
Goal
- Studying SQL for data analysis
- Practicing chapter 3rd in the book
- Studying SQL for Manipulating data
Practice
Book for studying
| Title | 데이터 분석을 위한 SQL 레시피 |
|---|---|
| Author | Nagato Kasaki, Naoto Tamiya |
| Translator | 윤인성 |
| Publisher | 한빛미디어 |
| Chapter | 3 |
| Lesson | 6 |
- I’m gonna study basic SQL syntax and functions for data analysis
- I’m gonna study how to manipulate from a multiple values
- I’m gonna try to load test data on PostgreSQL and execute queries in the book
3.6. Manipulating multiple values
3.6.1. Concatenate strings
Create table and insert sample data
-- DROP TABLE IF EXISTS mst_user_location;
-- Create user location table
CREATE TABLE mst_user_location (
user_id varchar(255)
, pref_name varchar(255)
, city_name varchar(255)
);
-- Insert sample data
INSERT INTO mst_user_location
VALUES
('U001', 'Seoul-si', 'Seodaemun-gu')
, ('U002', 'Kyeonki-do Suwon-si', 'Paldal-gu' )
, ('U003', 'Jeju-do', 'Seoguipo-si')
;
commit;
-- Select sample data
SELECT *
FROM mst_user_location
;
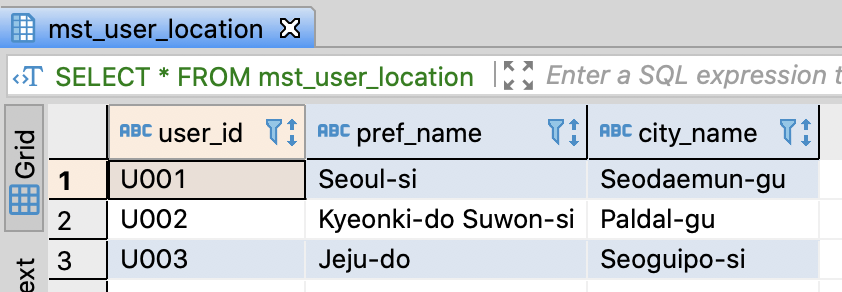
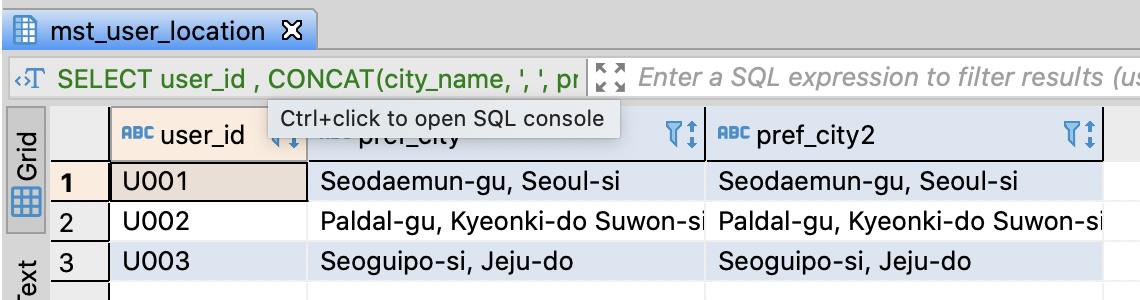
Concatenate string data type columns
-- Concatenate pref_name and citiy_name
SELECT user_id
-- if PostgreSQL, Hive, SparkSQL, BigQuery
, CONCAT(city_name, ', ', pref_name) AS pref_city
-- if PostgreSQL, Redshift
, city_name || ', ' || pref_name AS pref_city2
FROM mst_user_location
;
Redshift also supports CONCAT function. However, this function in Redshift allows only 2 arguments.
eg. CONCAT(‘a’, ‘b’) (O)
eg. CONCAT(‘a’, ‘b’, ‘c’) (X)
3.6.2. Compare multiple values
Create table and insert sample data
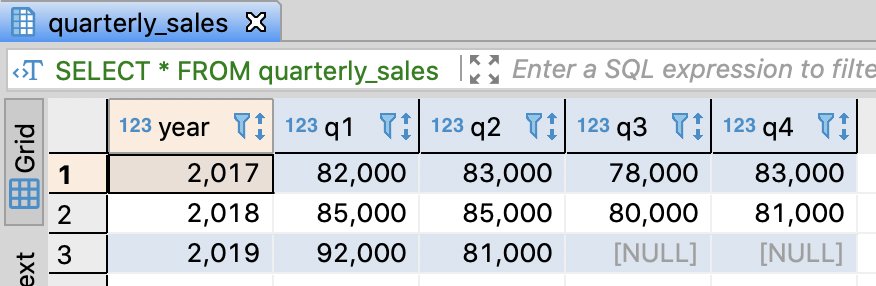
- Data in this table illustrates quarterly sales
- Null means that the sales haven’t been confirmed yet
-- DROP TABLE IF EXISTS quarterly_sales;
-- Create quarterly sales table
CREATE TABLE quarterly_sales (
year integer
, q1 integer
, q2 integer
, q3 integer
, q4 integer
);
-- Insert sample data
INSERT INTO quarterly_sales
VALUES
(2017, 82000, 83000, 78000, 83000)
, (2018, 85000, 85000, 80000, 81000)
, (2019, 92000, 81000, NULL , NULL )
;
-- Select sample data
SELECT *
FROM quarterly_sales
;
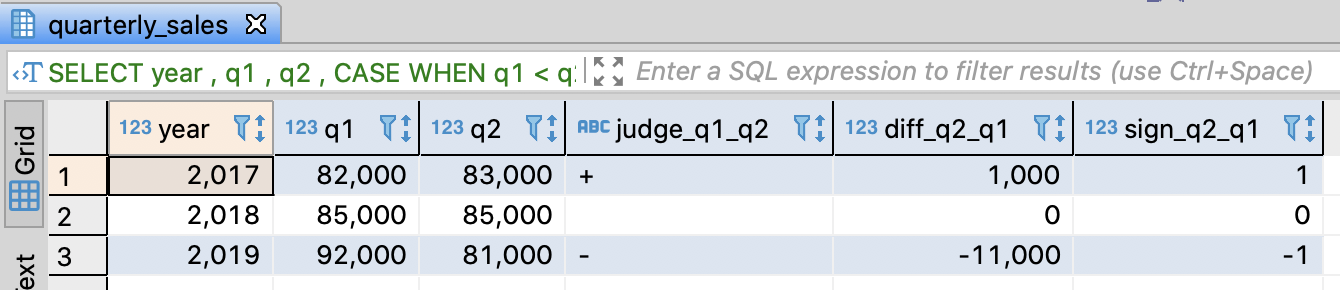
Find out whether the sales of a quater increased or decreased
- Print ‘+’ when sales increased and print ‘-‘ when sales decreased. And also, if there was no change, print ‘ ‘(space)
- You can use CASE and also SIGN function is available
- SIGN returns 1 from a positive number argument or -1 from a negative number one or 0 from 0 argument
-- Find out the fluctuation of sales quaterly
SELECT year
, q1
, q2
, CASE WHEN q1 < q2 THEN '+'
WHEN q1 = q2 THEN ' '
ELSE '-'
END AS judge_q1_q2
, q2 - q1 AS diff_q2_q1
, SIGN(q2 - q1) AS sign_q2_q1
FROM quarterly_sales
ORDER BY year
;
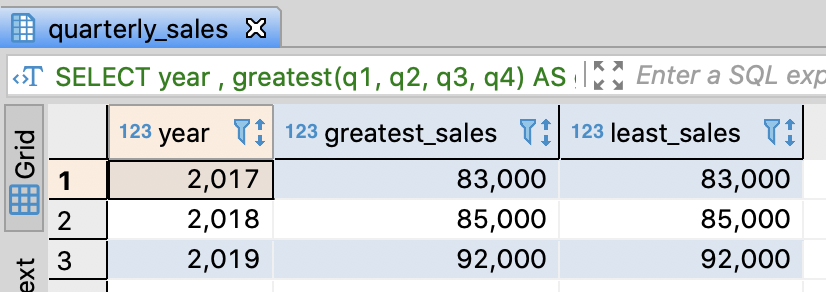
Extract maximum and minimum sales
- You can utilize greatest, least functions
- These functions are not the standard SQL, but most SQL query engines support them
-- Find out the max/min sales of a year
SELECT year
-- Maximum sales
, greatest(q1, q2, q3, q4) AS greatest_sales
-- Minimum sales
, greatest(q1, q2, q3, q4) AS least_sales
FROM quarterly_sales
ORDER BY year
;
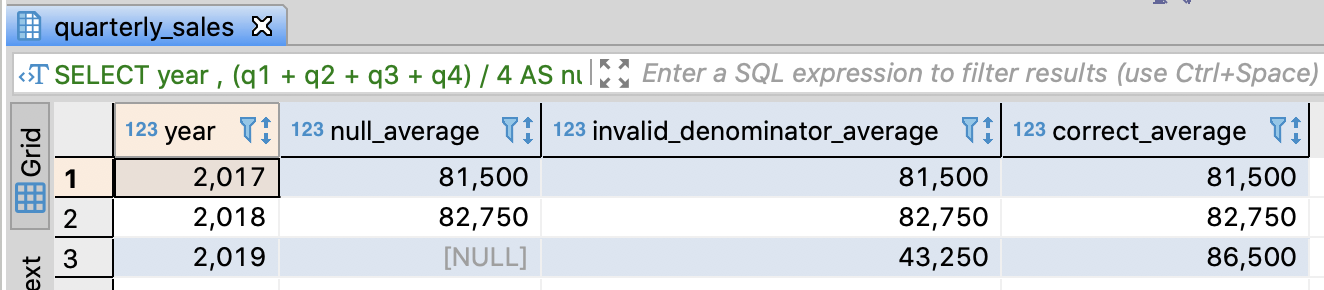
Calculate the average of a year
- You have to consider whether null value is exists or not
-- Calculate the average of a year
SELECT year
-- Invalid: It doesn't replace null to 0. The result of an arithmetic operation with null is null
, (q1 + q2 + q3 + q4) / 4 AS null_average
-- Invalid: You have to skip q3, q4 in 2019. But, it always divide total value into 4
, (COALESCE(q1, 0) + COALESCE(q2, 0) + COALESCE(q3, 0) + COALESCE(q4, 0)) / 4 AS invalid_denominator_average
-- Valid
, (COALESCE(q1, 0) + COALESCE(q2, 0) + COALESCE(q3, 0) + COALESCE(q4, 0))
/ (SIGN(COALESCE(q1, 0)) + SIGN(COALESCE(q2, 0)) + SIGN(COALESCE(q3, 0)) + SIGN(COALESCE(q4, 0))) AS correct_average
FROM quarterly_sales
ORDER BY year
;
3.6.3. Calculate the proportion
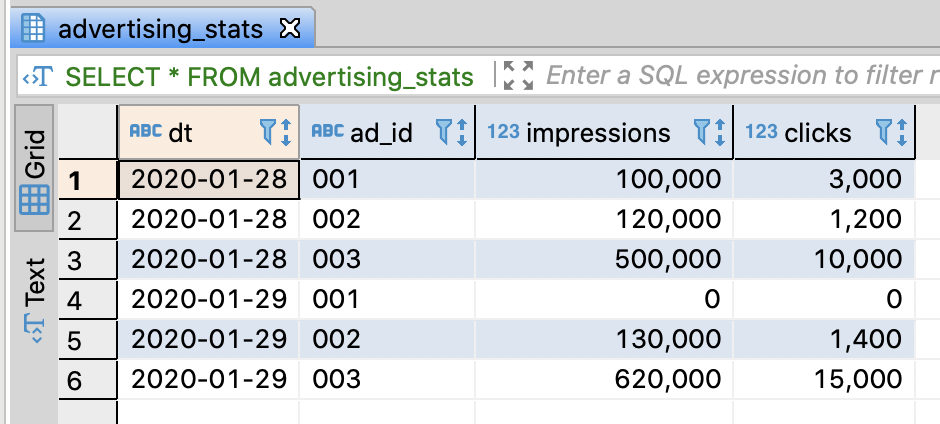
Create table and insert sample data
--DROP TABLE IF EXISTS advertising_stats;
-- Create advertising status table
CREATE TABLE advertising_stats (
dt varchar(255)
, ad_id varchar(255)
, impressions integer
, clicks integer
);
-- Insert sample data
INSERT INTO advertising_stats
VALUES
('2020-01-28', '001', 100000, 3000)
, ('2020-01-28', '002', 120000, 1200)
, ('2020-01-28', '003', 500000, 10000)
, ('2020-01-29', '001', 0, 0)
, ('2020-01-29', '002', 130000, 1400)
, ('2020-01-29', '003', 620000, 15000)
;
commit;
-- Select sample data
SELECT *
FROM advertising_stats
;
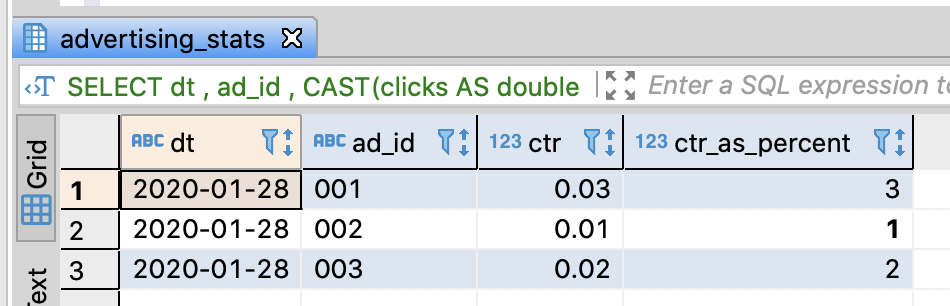
Calculate CTR(Clikc Through Rate)
- CTR : The frequency of clicks / The frequency of exposure(impression)
- clicks and impression column are integer type
- To get double presion result, you have to convert integer into double through CAST function
- Hive, SparkSQL, Redshift, BigQuery support auto conversion when an integer number is divided by an integer number, while you have to convert type explicitly in PostgreSQL
-- Calculate CTR(Click through rate)
SELECT dt
, ad_id
, CAST(clicks AS double precision) / impressions AS ctr
-- 100.0(double) * clicks(integer) -> double
, 100.0 * clicks / impressions AS ctr_as_percent
-- if Hive, SparkSQL, Redshift, BigQuery => Auto conversion
-- , clicks / impressions AS ctr
FROM advertising_stats
WHERE dt = '2020-01-28'
ORDER BY dt, ad_id
;
Be careful to divide by zero
- If you try to divide clicks by zero, you’ll face the error like below
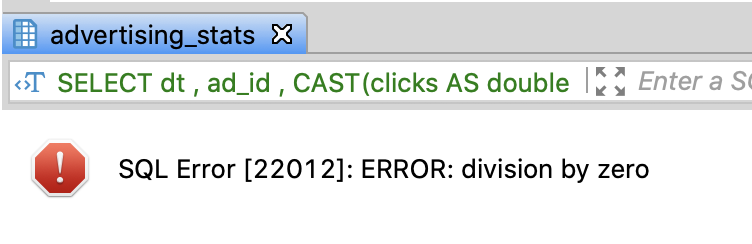
- To avoid this error, you have to replace 0 with null through CASE or NULLIF function
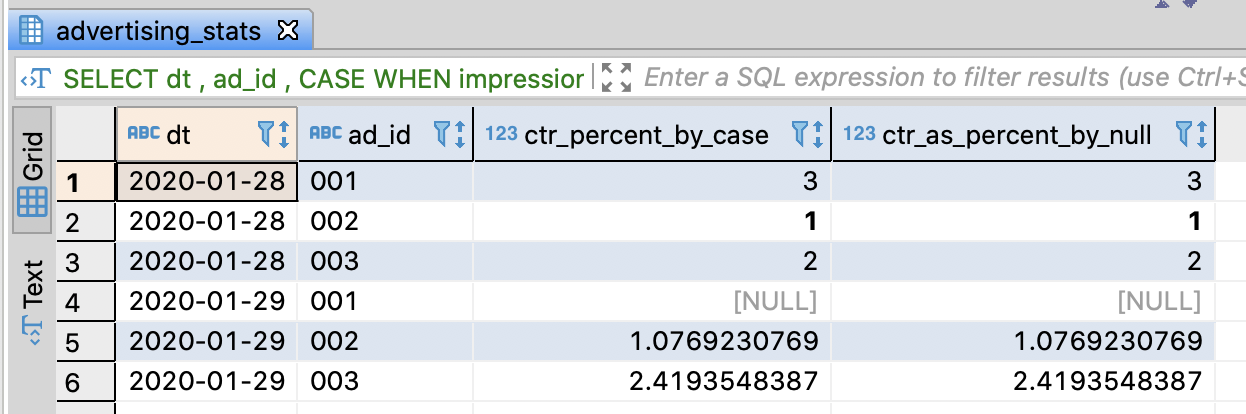
-- Calculate CTR without error
SELECT dt
, ad_id
-- use CASE clause
, CASE WHEN impressions > 0 THEN 100.0 * clicks / impressions
END AS ctr_percent_by_case
-- if PostgreSQL, SparkSQL, Redshift, BigQuery
-- The result of arithmetic operation with null is null
, 100.0 * clicks / NULLIF(impressions , 0) AS ctr_as_percent_by_null
-- if Hive (Not support NULLIF)
-- , 100.0 * clicks / CASE WHEN imperssions = 0 THEN NULL ELSE impressions END AS ctr_as_percent_by_null
FROM advertising_stats
ORDER BY dt, ad_id
;
3.6.4. Calculate the distance between two points
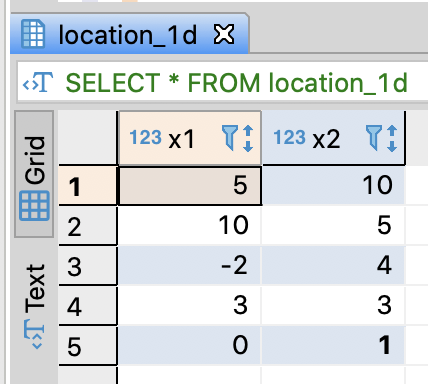
Create a dimension table and insert sample data
-- DROP TABLE IF EXISTS location_1d;
-- Create a dimension table
CREATE TABLE location_1d (
x1 integer
, x2 integer
);
-- Insert sample data
INSERT INTO location_1d
VALUES
( 5 , 10)
, (10 , 5)
, (-2 , 4)
, ( 3 , 3)
, ( 0 , 1)
;
commit;
-- Select sample data
SELECT *
FROM location_1d
;
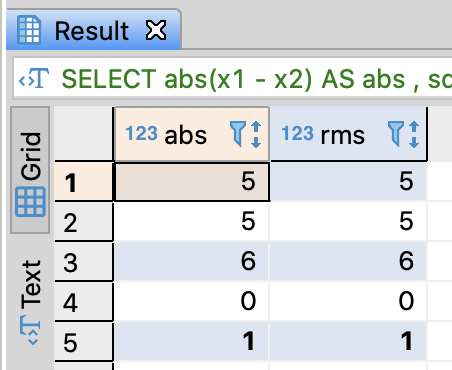
Calculate the distance between x1 and x2
- You can utilize ABS, POWER, SQRT functions
| Function | Description |
|---|---|
| ABS | Return absolute-value |
| POWER | Return the square of parameter value |
| SQRT | Return the square root of parameter value |
-- Calculate the distance between x1 and x2
SELECT abs(x1 - x2) AS abs
, sqrt(power(x1 - x2, 2)) AS rms
FROM location_1d
;
Create two dimensions table and insert sample data
-- DROP TABLE IF EXISTS location_2d;
-- Create two dimensions table
CREATE TABLE location_2d (
x1 integer
, y1 integer
, x2 integer
, y2 integer
);
-- Insert sample data
INSERT INTO location_2d
VALUES
(0, 0, 2, 2)
, (3, 5, 1, 2)
, (5, 3, 2, 1)
;
commit;
-- Select sample data
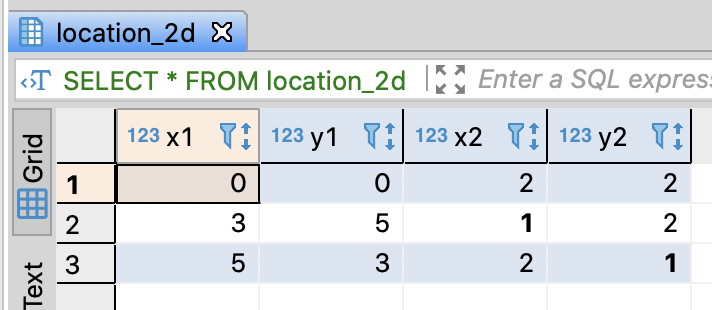
SELECT *
FROM location_2d
;
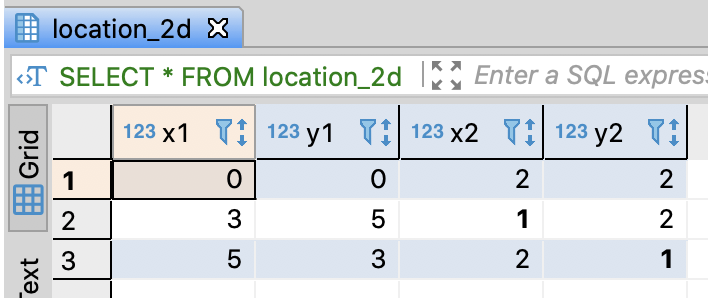
Calculate the Euclidean distance between (x1, y1) and (x2, y2)
- You can calculate it through POWER and SQRT
- PostgreSQL supports POINT data type and <–> the distance operation
-- Calculate the Euclidean distance between (x1, y1) and (x2, y2)
SELECT sqrt(power(x1 - x2, 2) + power(y1 - y2, 2)) AS distance
, point(x1, y1) <-> point(x2, y2) as dist_point
FROM location_2d
;
3.6.5. Calculate Date/Time
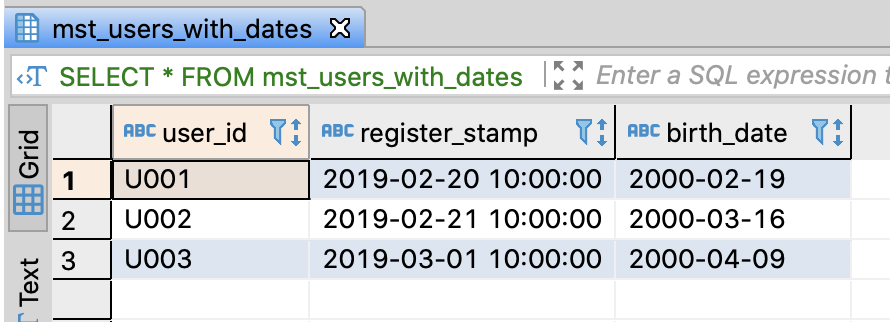
Create table and insert sample data
-- DROP TABLE IF EXISTS mst_users_with_dates;
-- Create user table with user's birthday and register datetime
CREATE TABLE mst_users_with_dates (
user_id varchar(255)
, register_stamp varchar(255)
, birth_date varchar(255)
);
-- Insert sample data
INSERT INTO mst_users_with_dates
VALUES
('U001', '2019-02-20 10:00:00', '2000-02-19')
, ('U002', '2019-02-21 10:00:00', '2000-03-16')
, ('U003', '2019-03-01 10:00:00', '2000-04-09')
;
commit;
-- Select sample data
SELECT *
FROM mst_users_with_dates
;
Calculate date/time
- Hive, SparkSQL don’t support date/time functions. So, you have to convert string data into unixtime and convert it into timestamp data type
-- Calculate date/time
SELECT user_id
, register_stamp::timestamp AS register_stamp
, register_stamp::timestamp + '1 hour'::interval AS after_1_hour
, register_stamp::timestamp - '30 minutes'::interval AS before_30_minutes
, register_stamp::date AS register_date
, register_stamp::date + '1 day'::interval AS after_1_day
, register_stamp::date - '1 month'::interval AS before_1_month
--
-- if Hive, SparkSQL (Not support timstamp operation functions)
-- , CAST(register_stamp AS timestamp) AS register_stamp
-- , from_unixtime(unix_tiestamp(register_stamp) + 60 * 60) AS after_1_hour
-- , from_unixtime(unix_tiestamp(register_stamp) - 30 * 60) AS before_30_minutes
-- , to_date(register_stamp) AS register_date
-- , date_add(to_date(register_stamp), 1) AS after_1_day
-- , add_months(to_date(register_stamp), -1) AS before_1_month
--
-- if Redshift (dateadd)
-- , register_stamp::timestamp AS register_stamp
-- , dateadd(hour, 1, register_stamp::timestamp) AS after_1_hour
-- , dateadd(minute, -30, register_stamp::timestamp) AS before_30_minutes
-- , register_stamp::date AS register_date
-- , dateadd(day, 1, register_stamp::date) AS after_1_day
-- , dateadd(month, -1, register_stamp::date) AS before_1_month
--
-- if BigQuery (timestamp_add, timestamp_sub, date_add, date_sub)
-- , timestamp(register_stamp) AS register_stamp
-- , timestamp_add(timestamp(register_stamp), interval 1 hour) AS after_1_hour
-- , timestamp_sub(timestamp(register_stamp), interval 30 minute) AS before_30_minutes
-- , date(register_stamp) AS register_date
-- , date_add(date(register_stamp), interval 1 day) AS after_1_day
-- , date_sub(date(register_stamp), interval 1 month) AS before_1_month
FROM mst_users_with_dates
;

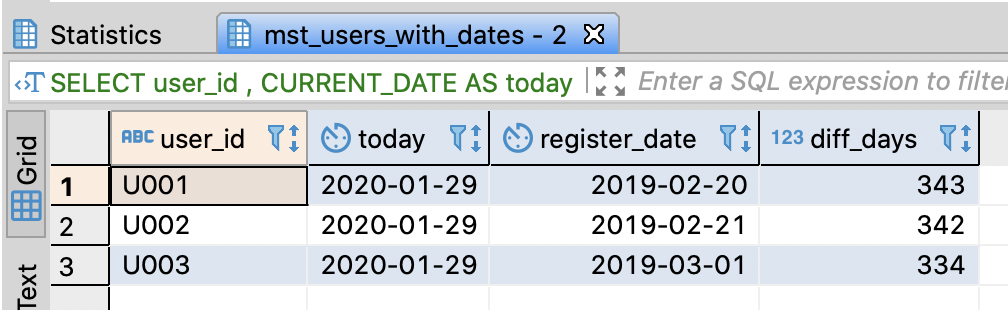
Calculate the difference between date/time data
-- Calculate the difference between today and register_stamp
SELECT user_id
-- if PostgreSQL, Redshift
, CURRENT_DATE AS today
, register_stamp::date AS register_date
, CURRENT_DATE - register_stamp::date AS diff_days
--
-- if Hive, SparkSQL (datediff)
-- , CURRENT_DATE() AS today
-- , to_date(register_stamp) AS register_date
-- , datediff(CURRENT_DATE(), to_date(register_stamp)) AS diff_days
--
-- if BigQuery (date_diff)
-- , CURRENT_DATE AS today
-- , date(timestamp(register_stamp)) AS register_date
-- , date_diff(CURRENT_DATE, date(timestamp(register_stamp)), day) AS diff_days
FROM mst_users_with_dates muwd
;
Calculate user’s age from the birthday
- PostgreSQL supports age function and it returns days
- age(arg) -> current age from arg
- arg(arg1, arg2) -> age from arg1 to arg2
Redshift also supports age function, but it is not official
- You can get YEAR through EXTRACT function
-- Calculate user's age from the birthday
SELECT user_id
, CURRENT_DATE AS today
, register_stamp::date AS register_date
, birth_date::date AS birth_date
, EXTRACT(YEAR FROM age(birth_date::date)) AS current_age
, EXTRACT(YEAR FROM age(register_stamp::date, birth_date::date)) AS register_age
, age(register_stamp::date, birth_date::date) AS register_age2
FROM mst_users_with_dates muwd
;

Calculate year difference
- Redshift has datediff and BigQuery has date_diff function for getting the year difference
- However, it is not exact to calculate the age because it just returns the year difference
- eg. datediff(year, ‘2019-12-31’, ‘2020-01-01’) returns 1, nevertheless the age is 0
-- Calculate year difference
SELECT user_id
-- if Redshift
, CURRENT_DATE AS today
, register_stamp::date AS register_date
, birth_date::date AS birth_date
, datediff(year, birth_date::date, CURRENT_DATE) AS current_age
, datediff(year, birth_date::date, register_stamp::date) AS register_age
--
-- if BigQuery
-- , CURRENT_DATE AS today
-- , date(timestamp(register_stamp)) AS register_date
-- , date(timestamp(birth_date)) AS birth_date
-- , date_diff(CURRENT_DATE, date(tiemstamp(birth_date)), year) AS current_age
-- , date_diff(date(timestamp(registeR_stamp)), date(timestamp(birth_date)), year) AS register_age
FROM mst_users_with_dates
;
How to calculate the age exactly without a special function like age
- It is possible to get exact age by converting date into integer
-- How to calculate the age exactly without a special function like age
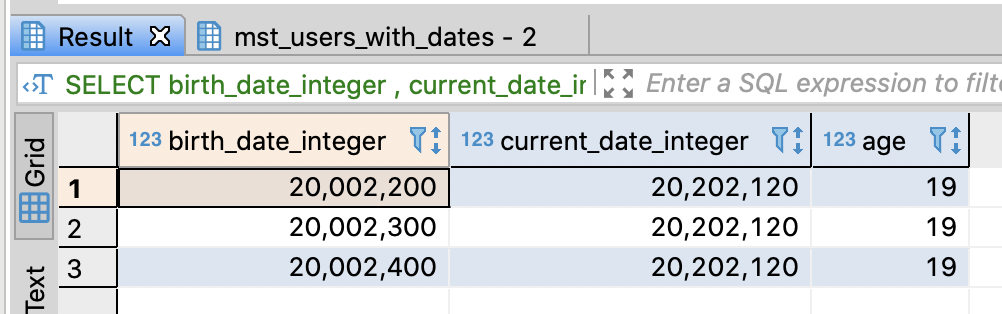
SELECT birth_date_integer
, current_date_integer
, floor((current_date_integer - birth_date_integer) / 10000) AS age
FROM (SELECT EXTRACT(YEAR from birth_date::date) * 10000 + EXTRACT(MONTH from birth_date::date) * 100 + EXTRACT(YEAR from birth_date::date) AS birth_date_integer
, EXTRACT(YEAR from CURRENT_DATE) * 10000 + EXTRACT(MONTH from CURRENT_DATE) * 100 + EXTRACT(YEAR from CURRENT_DATE) AS current_date_integer
FROM mst_users_with_dates muwd)
;
3.6.6. Handle IP address
- There are many log data which has IP addresses
- Generally, IP address is stored as string data type. But, there are lots of cases to compare IP addresses
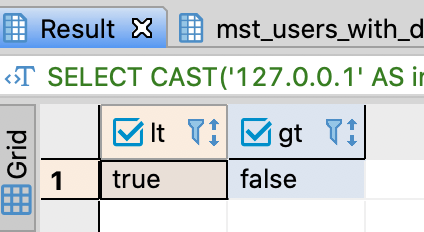
Use IP address data type
- PostgreSQL supports inet data type which is useful to compare IP addresses
-- Compare IP addresses
SELECT CAST('127.0.0.1' AS inet) < CAST('127.0.0.2' AS inet) AS lt
, CAST('127.0.0.1' AS inet) > CAST('192.168.0.1' AS inet) AS gt
;
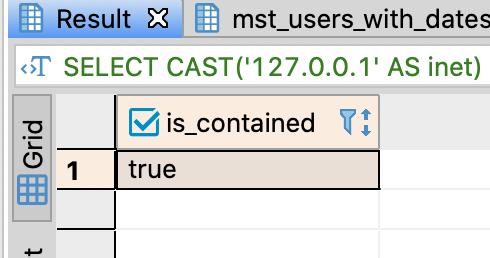
- Find out whether an IP address is contained or not using « or » functions
-- Find out whether an IP address is contained or not
SELECT CAST('127.0.0.1' AS inet) << CAST('127.0.0.0/8' AS inet) AS is_contained;
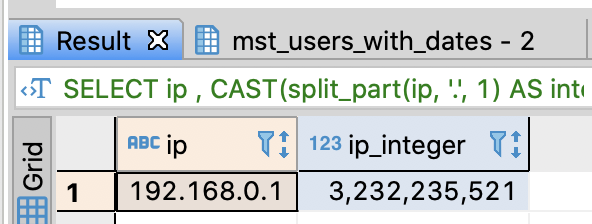
Handle IP address as integer or string
- Convert IP address into integer data type
-- Convert IP address into integer data type
SELECT ip
-- if PostgreSQL, Redshift (split_part)
, CAST(split_part(ip, '.', 1) AS integer) AS ip_part_1
, CAST(split_part(ip, '.', 2) AS integer) AS ip_part_2
, CAST(split_part(ip, '.', 3) AS integer) AS ip_part_3
, CAST(split_part(ip, '.', 4) AS integer) AS ip_part_4
--
-- if Hive, SparkSQL
-- , CAST(split(ip, '\\.')[0] AS int) AS ip_part_1
-- , CAST(split(ip, '\\.')[1] AS int) AS ip_part_2
-- , CAST(split(ip, '\\.')[2] AS int) AS ip_part_3
-- , CAST(split(ip, '\\.')[3] AS int) AS ip_part_4
--
-- if BigQuery
-- , CAST(split(ip, '.')[0] AS int) AS ip_part_1
-- , CAST(split(ip, '.')[1] AS int) AS ip_part_2
-- , CAST(split(ip, '.')[2] AS int) AS ip_part_3
-- , CAST(split(ip, '.')[3] AS int) AS ip_part_4
FROM (SELECT CAST('192.168.0.1' AS text) AS ip) AS t
-- Other databases
-- (SELECT '192.168.0.1' AS ip) AS t
;

- You can get one integer from IP address
- Multiply 4 parts from IP address and 2^24, 2^16, 2^8, 2^0 respectively
-- Convert IP address into integer
SELECT ip
-- if PostgreSQL, Redshift (split_part)
, CAST(split_part(ip, '.', 1) AS integer) * 2^24
+ CAST(split_part(ip, '.', 2) AS integer) * 2^16
+ CAST(split_part(ip, '.', 3) AS integer) * 2^8
+ CAST(split_part(ip, '.', 4) AS integer) * 2^0
AS ip_integer
--
-- if Hive, SparkSQL
-- , CAST(split(ip, '\\.')[0] AS int) * pow(2, 24)
-- + CAST(split(ip, '\\.')[1] AS int) * pow(2, 16)
-- + CAST(split(ip, '\\.')[2] AS int) * pow(2, 8)
-- + CAST(split(ip, '\\.')[3] AS int) * pow(2, 0)
--
-- if BigQuery
-- , CAST(split(ip, '.')[SAFE_ORDINAL(1)] AS int64) * pow(2, 24)
-- + CAST(split(ip, '.')[SAFE_ORDINAL(2)] AS int64) * pow(2, 16)
-- + CAST(split(ip, '.')[SAFE_ORDINAL(3)] AS int64) * pow(2, 8)
-- + CAST(split(ip, '.')[SAFE_ORDINAL(4)] AS int64) * pow(2, 0)
-- AS ip_integer
FROM (SELECT CAST('192.168.0.1' AS text) AS ip) AS t
-- Other databases
-- (SELECT '192.168.0.1' AS ip) AS t
;
- Convert IP address into string with 0 padding
-- Convert IP address into string with 0 padding
SELECT ip
-- if PostgreSQL, Redshift (lpad)
, lpad(split_part(ip, '.', 1), 3, '0')
|| lpad(split_part(ip, '.', 2), 3, '0')
|| lpad(split_part(ip, '.', 3), 3, '0')
|| lpad(split_part(ip, '.', 4), 3, '0')
AS ip_padding
--
-- if Hive, SparkSQL
-- , CONCAT(lpad(split(ip, '\\.')[0], 3, '0')
-- , lpad(split(ip, '\\.')[1], 3, '0')
-- , lpad(split(ip, '\\.')[2], 3, '0')
-- , lpad(split(ip, '\\.')[3], 3, '0')
-- ) AS ip_padding
--
-- if BigQuery
-- , CONCAT(lpad(split(ip, '.')[SAFE_ORDINAL(1)], 3, '0')
-- , lpad(split(ip, '.')[SAFE_ORDINAL(2)], 3, '0')
-- , lpad(split(ip, '.')[SAFE_ORDINAL(3)], 3, '0')
-- , lpad(split(ip, '.')[SAFE_ORDINAL(4)], 3, '0')
-- ) AS ip_padding
FROM (SELECT CAST('192.168.0.1' AS text) AS ip) AS t
-- Other databases
-- (SELECT '192.168.0.1' AS ip) AS t
;

References
- 데이터 분석을 위한 SQL 레시피 - 한빛미디어
댓글남기기