[Data Analysis] SQL Recipe for Data Analysis Tutorial #5 - Manipulating multiple tables
Goal
- Studying SQL for data analysis
- Practicing chapter 3rd in the book
- Studying SQL for Manipulating data
Practice
Book for studying
| Title | 데이터 분석을 위한 SQL 레시피 |
|---|---|
| Author | Nagato Kasaki, Naoto Tamiya |
| Translator | 윤인성 |
| Publisher | 한빛미디어 |
| Chapter | 3 |
| Lesson | 8 |
- I’m gonna study basic SQL syntax and functions for data analysis
- I’m gonna study how to manipulate multiple tables
- I’m gonna study about data-intensive and data-processing
- I’m gonna try to load test data on PostgreSQL and execute queries in the book
3.8. Manipulating multiple tables
3.8.1. Merge several tables horizontally
Create two user table
- One of them is the table that stores information about users in application 1, while another table stores users in application 2
-- DROP TABLE IF EXISTS app1_mst_users;
-- Create user in app1 table
CREATE TABLE app1_mst_users (
user_id varchar(255)
, name varchar(255)
, email varchar(255)
);
-- Insert sample data
INSERT INTO app1_mst_users
VALUES
('U001', 'Dorbae', 'dorbae@example.com' )
, ('U002', 'Chang', 'chang@example.com')
;
-- DROP TABLE IF EXISTS app2_mst_users;
-- Create user in app2 table
CREATE TABLE app2_mst_users (
user_id varchar(255)
, name varchar(255)
, phone varchar(255)
);
-- Insert sample data
INSERT INTO app2_mst_users
VALUES
('U001', 'Seong', '080-xxxx-xxxx')
, ('U002', 'Bae', '070-xxxx-xxxx')
;
commit;
-- Select sample data
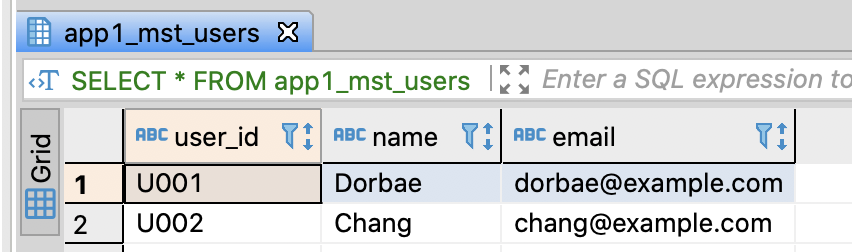
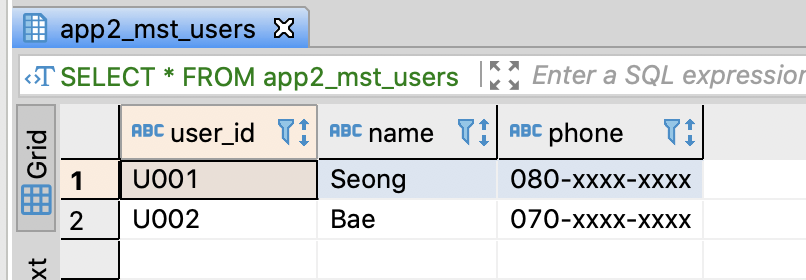
SELECT *
FROM app1_mst_users
;
SELECT *
FROM app2_mst_users
;
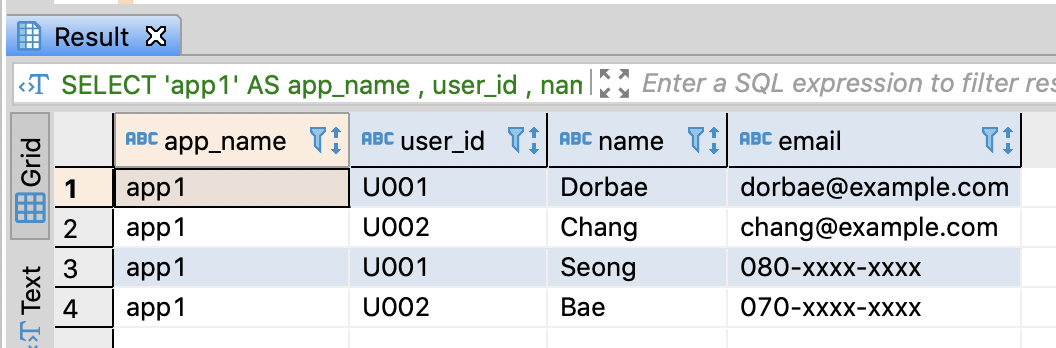
Merge tables
- You can merge several table throug UNION ALL
- UNION or UNION DISTINCT also merges multiple tables and in this case, it provides the same result. But, it spends more costs than UNION ALL
- I’m gonna add app_name column for indentifying the app
-- Merge two tables
SELECT 'app1' AS app_name
, user_id
, name
, email
FROM app1_mst_users
UNION ALL
SELECT 'app1' AS app_name
, user_id
, name
, phone -- or NULL
FROM app2_mst_users
;
3.8.2. Merge several tables vertically
Create three tables
-- DROP TABLE IF EXISTS mst_categories;
CREATE TABLE mst_categories (
category_id integer
, name varchar(255)
);
INSERT INTO mst_categories
VALUES
(1, 'dvd' )
, (2, 'cd' )
, (3, 'book')
;
-- DROP TABLE IF EXISTS category_sales;
CREATE TABLE category_sales (
category_id integer
, sales integer
);
INSERT INTO category_sales
VALUES
(1, 850000)
, (2, 500000)
;
-- DROP TABLE IF EXISTS product_sale_ranking;
CREATE TABLE product_sale_ranking (
category_id integer
, rank integer
, product_id varchar(255)
, sales integer
);
INSERT INTO product_sale_ranking
VALUES
(1, 1, 'D001', 50000)
, (1, 2, 'D002', 20000)
, (1, 3, 'D003', 10000)
, (2, 1, 'C001', 30000)
, (2, 2, 'C002', 20000)
, (2, 3, 'C003', 10000)
;
commit;
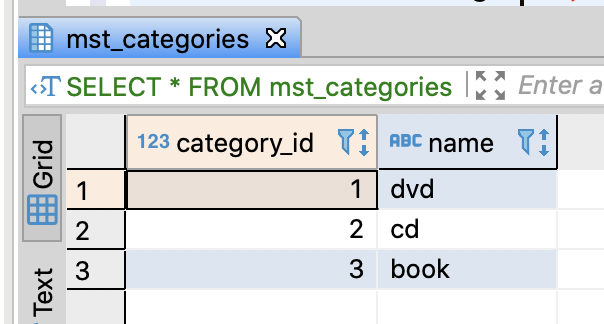
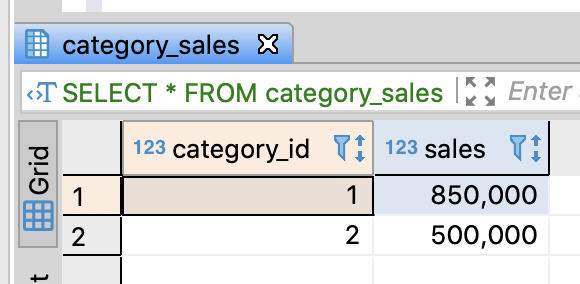
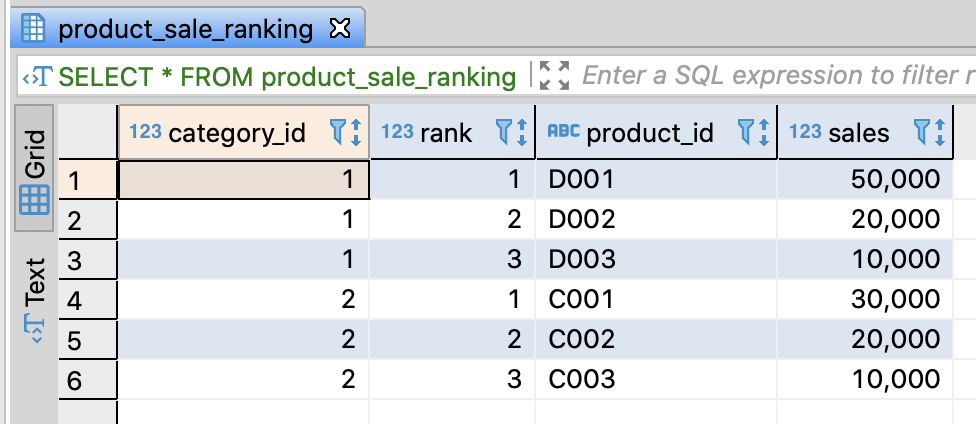
SELECT * FROM mst_categories;
SELECT * FROM category_sales;
SELECT * FROM product_sale_ranking;
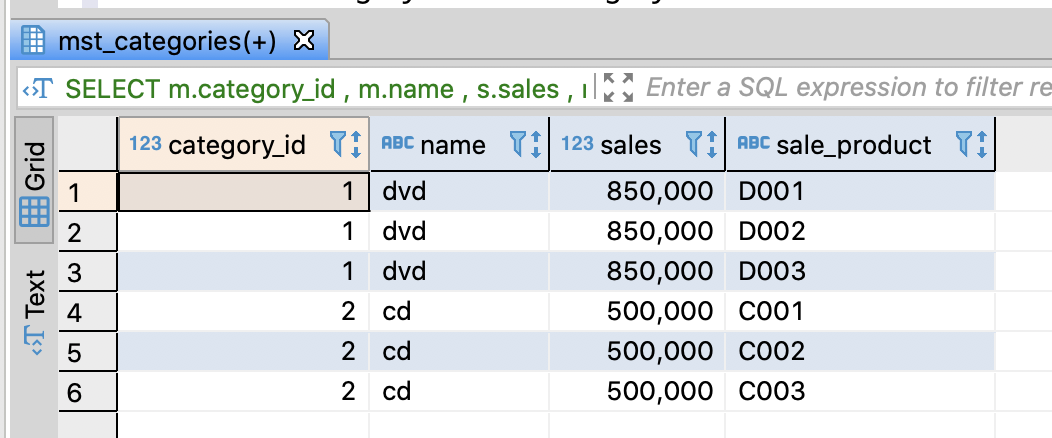
Merge the tables through JOIN
- You might loose some data because there are not matched data
-- Join tables
SELECT m.category_id
, m.name
, s.sales
, r.product_id AS sale_product
FROM mst_categories AS m
JOIN category_sales AS s
ON m.category_id = s.category_id
JOIN product_sale_ranking AS r
ON m.category_id = r.category_id
;
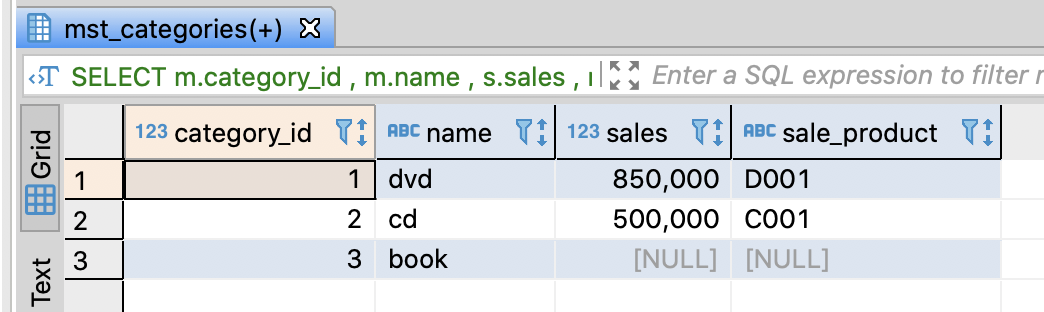
Merge the tables through LEFT JOIN
- You can maintain the record count of category_sales(basis table)
-- Join tables through LEFT JOIN
SELECT m.category_id
, m.name
, s.sales
, r.product_id AS sale_product
FROM mst_categories AS m
LEFT JOIN category_sales AS s
ON m.category_id = s.category_id
LEFT JOIN product_sale_ranking AS r
ON m.category_id = r.category_id
AND r.rank = 1
;
Merge the tables through Correlated Subquery without JOIN
- It is possible to use Correlated Subquery when the Middleware supports it
-- Merge tables through Correlated Subquery
SELECT m.category_id
, m.name
-- Calculate sales amount byt categories using Correlated Subquery
, (SELECT s.sales
FROM category_sales AS s
WHERE m.category_id = s.category_id
) AS sales
-- Best sales product by categories
-- Subquery has to return only one row
, (SELECT r.product_id
FROM product_sale_ranking AS r
WHERE m.category_id = r.category_id
ORDER BY sales DESC
LIMIT 1
) AS top_sale_product
FROM mst_categories AS m
;
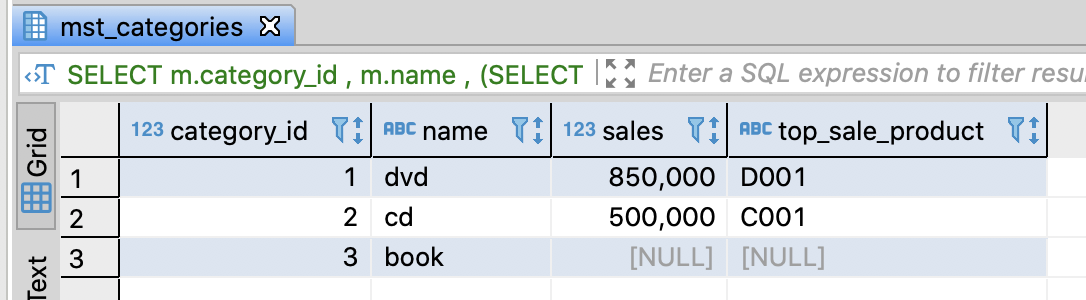
3.8.3. Convert a conditional flag into 0 or 1
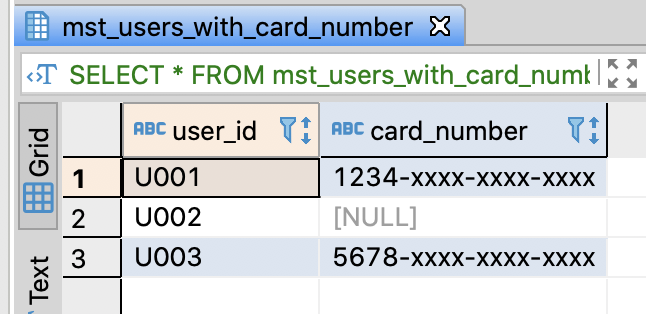
Create user with card number table and purchase log table
-- DROP TABLE IF EXISTS mst_users_with_card_number;
-- Create user with card number table
CREATE TABLE mst_users_with_card_number (
user_id varchar(255)
, card_number varchar(255)
);
-- Insert sample data
INSERT INTO mst_users_with_card_number
VALUES
('U001', '1234-xxxx-xxxx-xxxx')
, ('U002', NULL )
, ('U003', '5678-xxxx-xxxx-xxxx')
;
-- DROP TABLE IF EXISTS purchase_log;
-- Create purchase log table
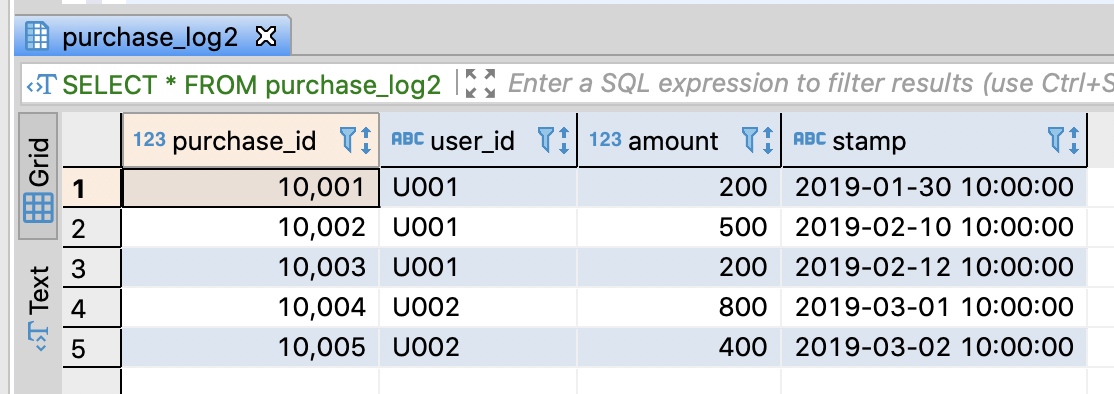
CREATE TABLE purchase_log2 (
purchase_id integer
, user_id varchar(255)
, amount integer
, stamp varchar(255)
);
INSERT INTO purchase_log2
VALUES
(10001, 'U001', 200, '2019-01-30 10:00:00')
, (10002, 'U001', 500, '2019-02-10 10:00:00')
, (10003, 'U001', 200, '2019-02-12 10:00:00')
, (10004, 'U002', 800, '2019-03-01 10:00:00')
, (10005, 'U002', 400, '2019-03-02 10:00:00')
;
commit;
-- Select sample data
SELECT * FROM mst_users_with_card_number;
SELECT * FROM purchase_log2;
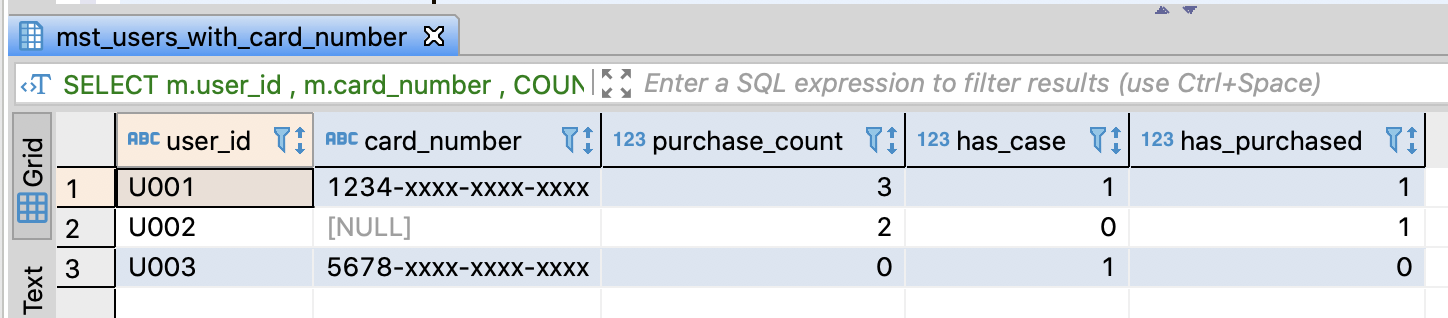
Convert boolean flag about purchase or not into 0/1
- You can maintain the same record count of mst_users_with_card_number by doing LEFT JOIN and GROUP BY user_id
- And, you can ocnvert a flag into 0/1 using CASE or SIGN function
- SIGN returns 0 if argument is 0 and returns 1 about a positive number argument and also returns -1 about a negative number argument
-- Convert boolean flag about purchase or not into 0/1
SELECT m.user_id
, m.card_number
, COUNT(p.user_id) AS purchase_count
-- If a card number was registered, return 1 and return 0 about the opposite case
, CASE WHEN m.card_number IS NOT NULL THEN 1
ELSE 0
END AS has_case
-- If user has been ever purchased, return 1 and return 0 about the opposite case
, SIGN(COUNT(p.user_id)) AS has_purchased
FROM mst_users_with_card_number AS m
LEFT JOIN purchase_log2 AS p
ON m.user_id = p.user_id
GROUP BY m.user_id, m.card_number
ORDER BY m.user_id
;
3.8.4. CTE(Common Table Expression)
- It has been introduced since SQL99
- It enhances a readability of the code
Create table and insert sample data
--DROP TABLE IF EXISTS product_sales;
-- Create product slaes table
CREATE TABLE product_sales (
category_name varchar(255)
, product_id varchar(255)
, sales integer
);
-- Insert sample data
INSERT INTO product_sales
VALUES
('dvd' , 'D001', 50000)
, ('dvd' , 'D002', 20000)
, ('dvd' , 'D003', 10000)
, ('cd' , 'C001', 30000)
, ('cd' , 'C002', 20000)
, ('cd' , 'C003', 10000)
, ('book', 'B001', 20000)
, ('book', 'B002', 15000)
, ('book', 'B003', 10000)
, ('book', 'B004', 5000)
;
commit;
-- Select sample data
SELECT * FROM product_sales;
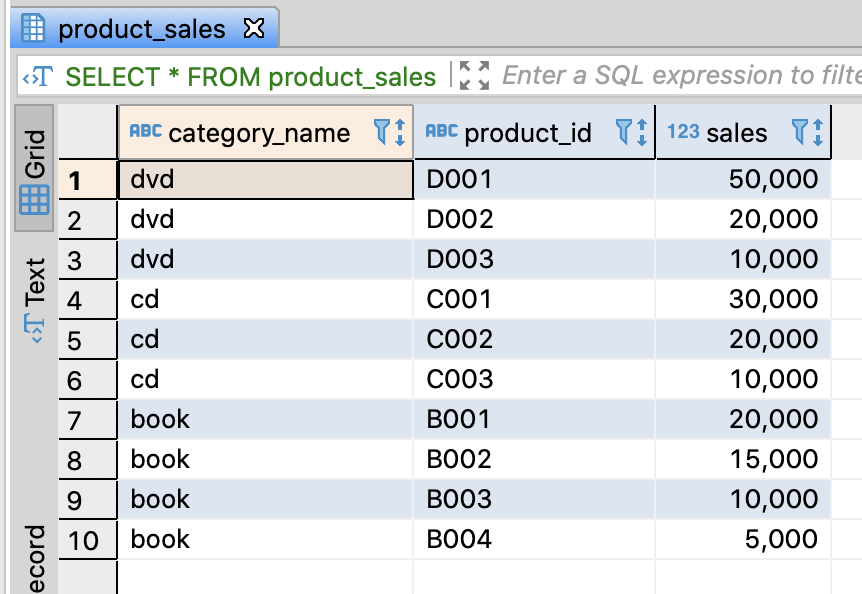
Set name to the table added the ranks by categories
-- Set name to the table added the ranks by categories
WITH
product_sale_ranking AS (
SELECT category_name
, product_id
, sales
, ROW_NUMBER()
OVER(PARTITION BY category_name ORDER BY sales DESC)
AS rank
FROM product_sales
)
SELECT *
FROM product_sale_ranking
;
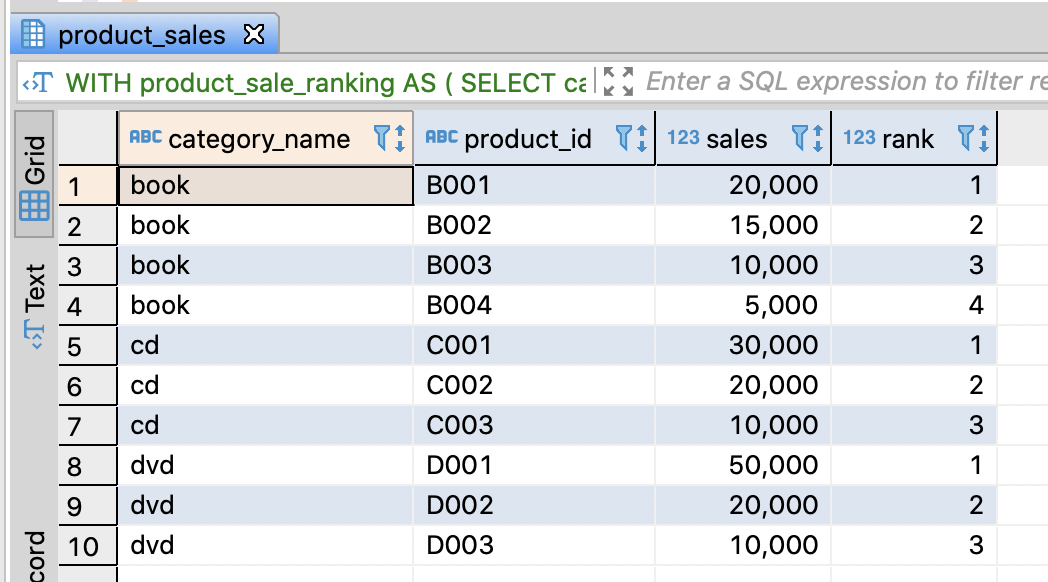
Extract the unique rankings from the ranking list by categories
-- Extract the unique rankings from the ranking list by categories
WITH
product_sale_ranking AS (
SELECT category_name
, product_id
, sales
, ROW_NUMBER()
OVER(PARTITION BY category_name ORDER BY sales DESC)
AS rank
FROM product_sales
)
, mst_rank AS (
SELECT DISTINCT rank
FROM product_sale_ranking
)
SELECT *
FROM mst_rank
;
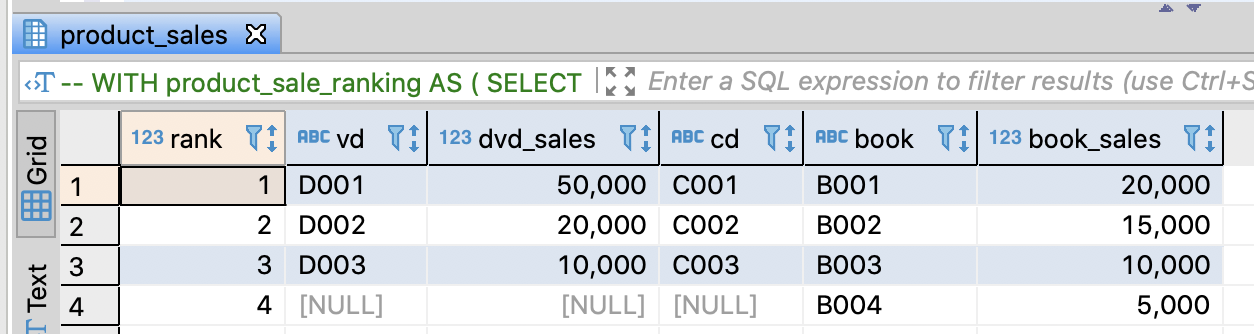
Print the ranking by categories
-- Print the ranking by categories
WITH
product_sale_ranking AS (
SELECT category_name
, product_id
, sales
, ROW_NUMBER()
OVER(PARTITION BY category_name ORDER BY sales DESC)
AS rank
FROM product_sales
)
, mst_rank AS (
SELECT DISTINCT rank
FROM product_sale_ranking
)
SELECT m.rank
, r1.product_id AS vd
, r1.sales AS dvd_sales
, r2.product_id AS cd
, r3.product_id AS book
, r3.sales AS book_sales
FROM mst_rank AS m
LEFT JOIN product_sale_ranking AS r1
ON m.rank = r1.rank
AND r1.category_name = 'dvd'
LEFT JOIN product_sale_ranking AS r2
ON m.rank = r2.rank
AND r2.category_name = 'cd'
LEFT JOIN product_sale_ranking AS r3
ON m.rank = r3.rank
AND r3.category_name = 'book'
ORDER BY m.rank
;
3.8.5. Make a resemblance table
- It can enhance the productivity performance for test
Make a resemblance table with specific records
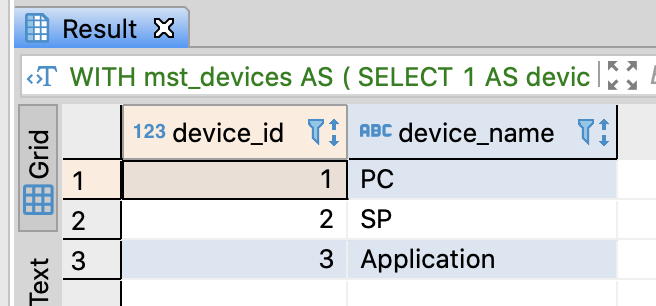
-- Make a resemblance table with specific records
WITH
mst_devices AS (
SELECT 1 AS device_id, 'PC' AS device_name
UNION ALL
SELECT 2 AS device_id, 'SP' AS device_name
UNION ALL
SELECT 3 AS device_id, 'Application' AS device_name
)
SELECT *
FROM mst_devices
;
UNION ALL might drop the performance whne there are a lot of records
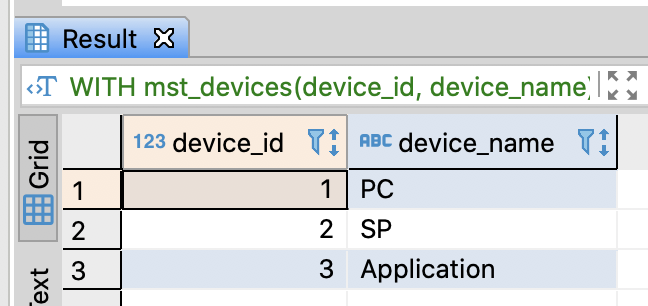
Make a resemblance table with VALUE clause
- In PostgreSQL, it is possible to make a resmeblance table using VALUES
-- Make a resemblance table with VALUE clause
WITH
mst_devices(device_id, device_name) AS (
VALUES
(1, 'PC')
, (2, 'SP')
, (3, 'Application')
)
SELECT *
FROM mst_devices
;
Make a resemblance table through structural table function
- You can make a dynamic table with a structural function when it is impossible to use VALUE clause
- For example, you can define a table through array function and explode function in Hive
-- Make a resemblance table through array, explode in Hive
WITH
mst_devces AS (
-- Convert a array into columns
SELECT d[0] AS device_id
, d[1] AS device_name
FROM (SELECT explode (
array(
array('1', 'PC')
, array('2', 'SP')
, array('3', 'Application')
)
) d
) AS t
)
SELECT *
FROM mst_devices
;
Use map data type intead of array data type
-- Use map data type intead of array data type
WITH
mst_devces AS (
SELECT d['device_id'] AS device_id
, d['device_name'] AS device_name
FROM (SELECT explode (
array(
map('device_id', '1', 'device_name', 'PC')
, map('device_id', '2', 'device_name', 'SP')
, map('device_id', '3', 'device_name', 'Application')
)
) d
) AS t
)
SELECT *
FROM mst_devices
;
The function making sequence numbers
- Some middleware support the function whixh makes sequence numbers
- PostgreSQL supports generate_series function and BigQuery supports generate_array function
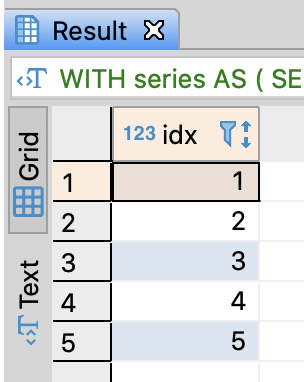
-- Make a resemblance table with sequence numbers
WITH
series AS (
-- Make from 1 to 5
SELECT generate_series(1, 5) AS idx
-- if BigQuery
-- SELECT idx FROM unnst(generate_array(1, 5)) AS idx
)
SELECT *
FROM series
;
Make a sequence numbers using repeat funxtion
- Hive and SparkSQL don’t support the function like generate_series
- Nevertheless, you cna make sequence numbers using repeat and explode functions
-- Make a resemblance table with sequence numbers through repeat
SELECT ROW_NUMBER()
OVER(ORDER BY x) AS idx
FROM
-- Make an array through repeat and split
-- After that, spread it through explode
(SELECT explode(split(repeat('x', 5 - 1), 'x')) AS x) AS t
;
References
- 데이터 분석을 위한 SQL 레시피 - 한빛미디어
댓글남기기