[CUBRID] How to install CUBRID in Linux
Goal
- Linux(CentOS)에 CUBRID 10.1 설치
- JDBC를 통한 DB 접속 테스트
들어가며
-
CUBRID는 관계형 DBMS로서 엔터프라이즈 시장에서 요구하는 대용량 데이터 처리 능력 및 성능, 안정성, 가용성, 관리 편의성을 제공하고 있습니다. ANSI SQL을 준수하고 있으며, 고가용성을 위한 HA (High-Availability) 기능, DB 관리 및 마이그레이션을 위한 GUI 기반의 각종 도구를 제공하고 있습니다. CUBRID는 3-tier 구조를 이루는 응용(Application) - 브로커(Broker) - 서버(Server)로 구성되며, 유연하게 시스템을 구축할 수 있어 데이터가 급증하는 온라인 트랜잭션 처리(OLTP: On-line Transaction Processing) 서비스에 적합합니다.
-
주요기능
- RDBMS 기본 기능 지원
- 트랜잭션 완벽 보장
- 장애 발생 및 백업 복구 시 트랜잭션 일치성 보장
- HA 환경에서 트랜잭션 일치성 보장
- ANSI SQL 표준 및 확장된 SQL 지원: 계층형 쿼리, CTE (Common Table Expression)를 이용한 재귀적 쿼리 등
- VIEW/TRIGGER/PRIMARY KEY/FOREIGN KEY/SERIAL 지원
- 고성능 보장
- MVCC (Multiversion Concurrency Control) 지원
- 멀티 쓰레드/멀티 서버 구조
- 브로커 미들웨어에 의한 커넥션 풀링/로드 밸런싱/Proxy 기능 지원
- 비용 기반 옵티마이저 지원(CBO)
- 쿼리 플랜 캐쉬 지원
- Disk I/O 최적화를 통한 성능 병목 구간 개선
- 고성능 인덱스(Multi-Range/Covered/Reverse/Skip-Scan/Function based/Filtered Index) 지원
- 대용량 및 확장성 보장
- 멀티 볼륨 및 볼륨 자동 추가 기능 지원
- DB/테이블/컬럼/인덱스 무제한 생성 가능
- 1:N 복제 구성을 통해 부하 분산 및 서비스 확장 가능
- 테이블 파티셔닝(Partitioning)을 통한 데이터 분할 관리 기능
- 안정성 및 운영 편의성 제공
- 온라인/오프라인 백업 및 복구 지원
- 증분 백업 지원 및 병렬/압축 백업 지원
- 장애 발생 시점 또는 특정 시점으로의 복구 지원
- 권한 상속을 통한 사용자/그룹별 권한 관리 기능
- HA 환경에서 장애 발생 시 자동절체(Auto-Failover) 지원
- HA 환경에서 Sync/Async 동작 모드 지원
- RDBMS 기본 기능 지원
Practice
1. CUBRID 설치
-
glibc 라이브러리 설치 확인 및 설치
$ rpm -qa | grep glibc

-
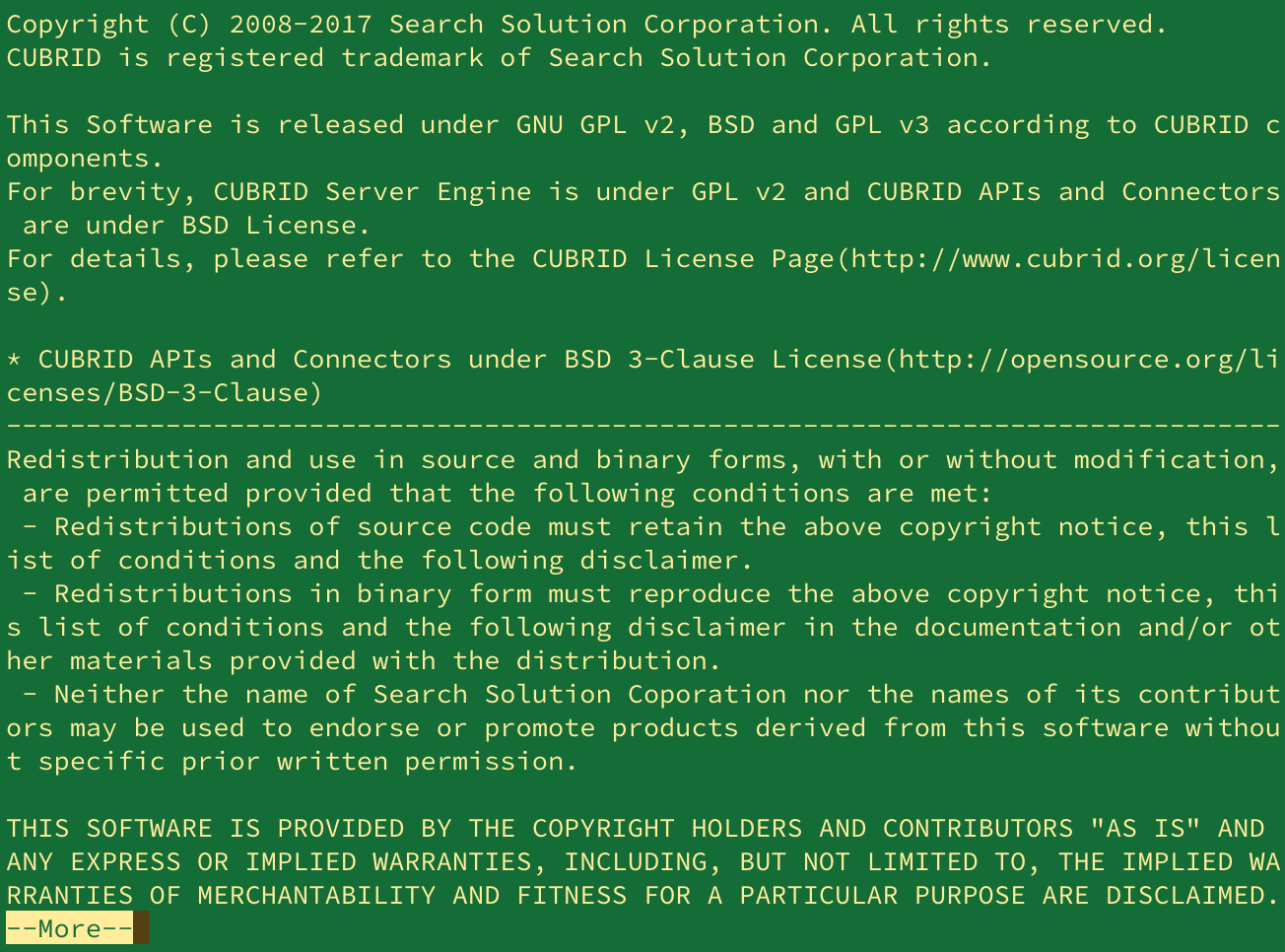
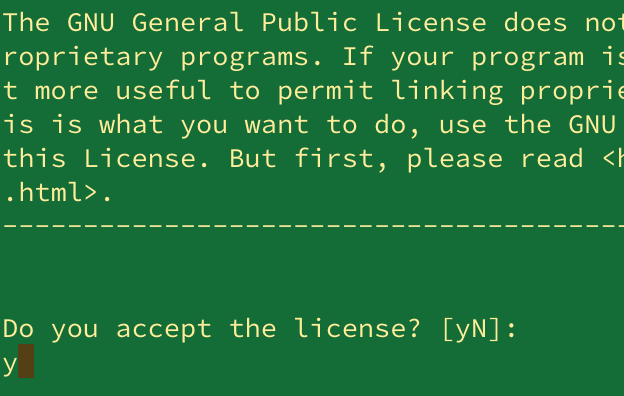
설치 파일 실행
$ sh [설치스크립트 파일]

- 설치 과정

- 환경변수 설정
$ vi ~/.cubrid.sh [copy] $ vi ~/.bash_profile [paste] $ . ~/.bash_profile


2. 데이터베이스 생성
- [자세한 createdb 명령어에 대한 설명]
- test DB 생성(https://www.cubrid.org/manual/ko/9.3.0/admin/admin_utils.html#creating-database)
$ cd $CUBRID_DATABASE $ mkdir [DATABASE_DIRECTORY_NAME] $ cd [DATABASE_DIRECTORY_NAME] $ cubrid createdb --db-volumn-size=[DB_SIZE] --log-volumn-size=[LOG_SIZE] [DB_NAME] [LOCALE.CHARSET]

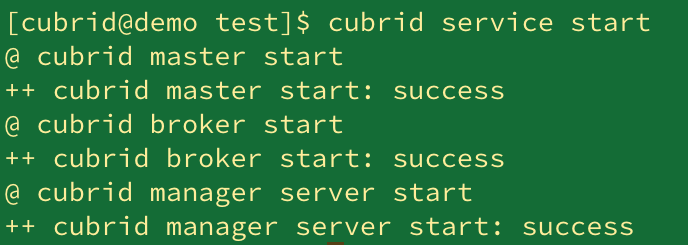
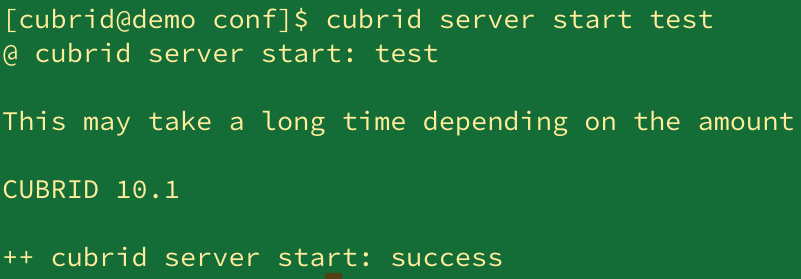
3. 서비스/DB 시작
- 서비스 시작
$ cubrid service start $ cubrid server start [DB_NAME]
4. CUBRID JDBC 접속 테스트
- DBeaver 통해서 CUBRID 접속

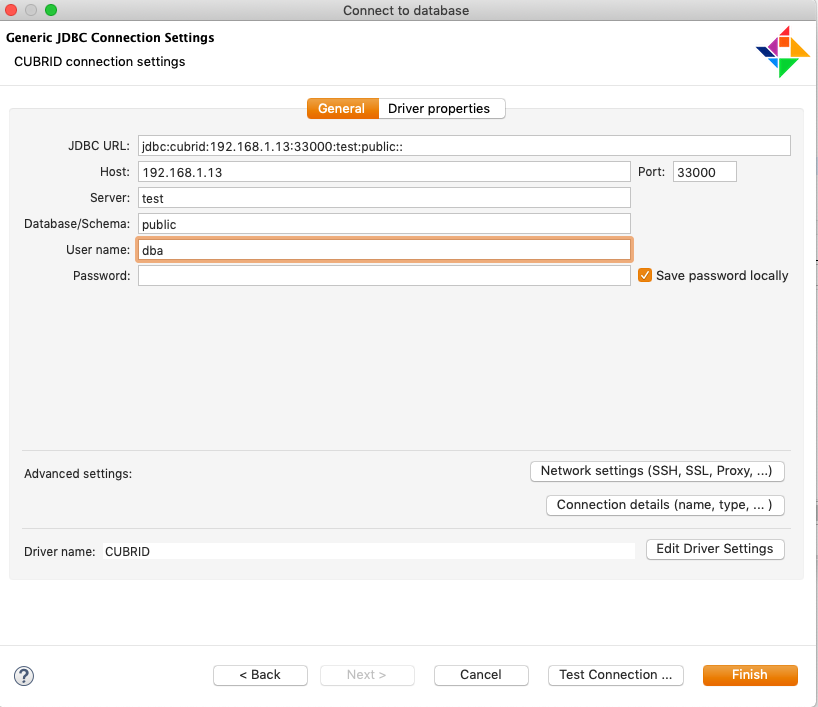
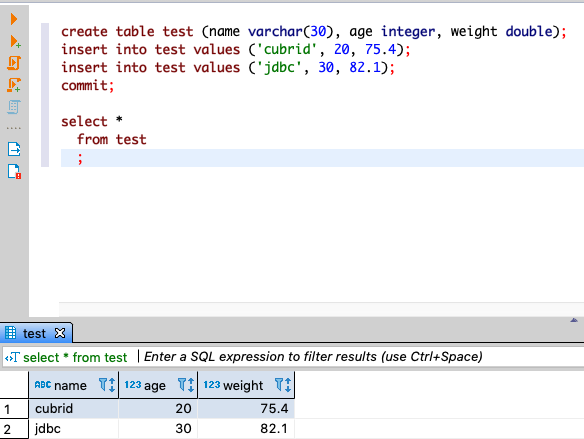
- 테이블 생성
댓글남기기