[Data Analysis] SQL Recipe for Data Analysis Tutorial #4 - Manipulating a single table
Goal
- Studying SQL for data analysis
- Practicing chapter 3rd in the book
- Studying SQL for Manipulating data
Practice
Book for studying
| Title | 데이터 분석을 위한 SQL 레시피 |
|---|---|
| Author | Nagato Kasaki, Naoto Tamiya |
| Translator | 윤인성 |
| Publisher | 한빛미디어 |
| Chapter | 3 |
| Lesson | 7 |
- I’m gonna study basic SQL syntax and functions for data analysis
- I’m gonna study how to manipulate a single table
- I’m gonna study about data-intensive and data-processing
- I’m gonna try to load test data on PostgreSQL and execute queries in the book
3.7. Manipulating a singlie table
- Data-intensive
- SQL supports a lot of functions for data-intensive
- Especially, SQL:2003 standard support Window functions which performs a calculation across a set of table rows that are somehow related to the current row
- Data-processing
- Sometimes, you need to convert a table as the form that you want because it is useful in an aggregation
3.7.1. Make groups
- Data-intensive means that making one value from multiple records like COUNT(returns total record count), SUM(returns the sum of all records)
Create table and insert sample data
--DROP TABLE IF EXISTS review;
-- Create review table
CREATE TABLE review (
user_id varchar(255)
, product_id varchar(255)
, score numeric
);
-- Insert sample data
INSERT INTO review
VALUES
('U001', 'A001', 4.0)
, ('U001', 'A002', 5.0)
, ('U001', 'A003', 5.0)
, ('U002', 'A001', 3.0)
, ('U002', 'A002', 3.0)
, ('U002', 'A003', 4.0)
, ('U003', 'A001', 5.0)
, ('U003', 'A002', 4.0)
, ('U003', 'A003', 4.0)
;
commit;
-- Select sample data
SELECT *
FROM review
;
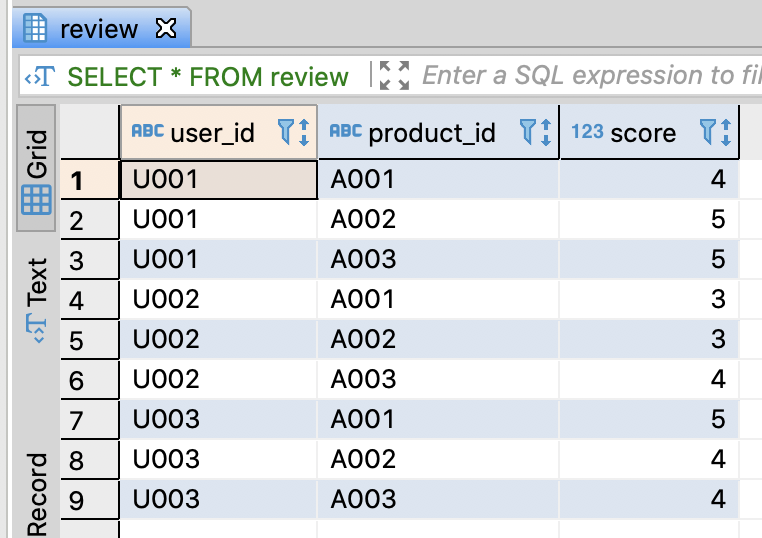
Calculate several feature values from all records
| Function | Description | | — | — | | DISTINCT | Removes the duplication | | SUM | Returns the sum | | AVG | Returns the average | | MAX | Returns the maximum value | | MIN | Returns the minimum value |
-- Calculate several feature values from all records
SELECT COUNT(*) AS total_count
, COUNT(DISTINCT user_id) AS user_count
, COUNT(DISTINCT product_id) AS product_count
, SUM(score) AS sum
, AVG(score) AS avg
, MAX(score) AS max
, MIN(score) AS min
FROM review
;

Calculate serveral feature values from groups repectively
- GROUP BY clause does intensivly by the key
- I’m gonna make groups by user_id
-- Calculate serveral feature values from groups repectively
SELECT user_id
, COUNT(*) AS total_count
, COUNT(DISTINCT product_id) AS product_count
, SUM(score) AS sum
, AVG(score) AS avg
, MAX(score) AS max
, MIN(score) AS min
FROM review
GROUP BY user_id
;

Handle the value that is applied data-intensive function and the one that is not applied it simultaneously
- I’ll calculate the difference between user’s private score(score) and the average score by user(user_avg_score)
- **OVER(PARTITION BY
)** : group by column_name - OVER() : about all records in a table
-- Calculate user's private score(score) and the average score by user(user_avg_score)
SELECT user_id
, product_id
-- User's private score
, score
-- The total average score
, AVG(score) OVER() AS avg_score
-- User's average score
, AVG(score) OVER(PARTITION BY user_id) AS user_avg_score
-- The differnce
, score - AVG(score) OVER(PARTITION BY user_id) AS user_avg_score_diff
FROM review
;
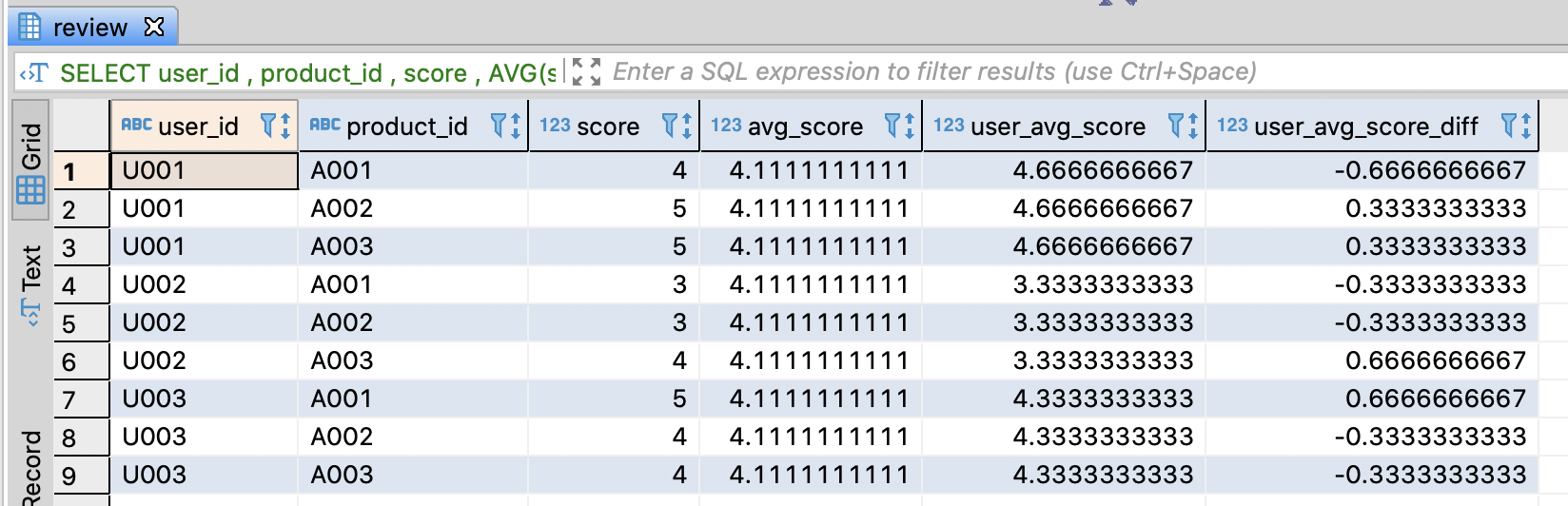
Create popular product table and insert sample data
-- DROP TABLE IF EXISTS popular_products;
-- Create popular product table
CREATE TABLE popular_products (
product_id varchar(255)
, category varchar(255)
, score numeric
);
-- Insert sample data
INSERT INTO popular_products
VALUES
('A001', 'action', 94)
, ('A002', 'action', 81)
, ('A003', 'action', 78)
, ('A004', 'action', 64)
, ('D001', 'drama' , 90)
, ('D002', 'drama' , 82)
, ('D003', 'drama' , 78)
, ('D004', 'drama' , 58)
;
commit;
-- Select sample data
SELECT *
FROM popular_products
;
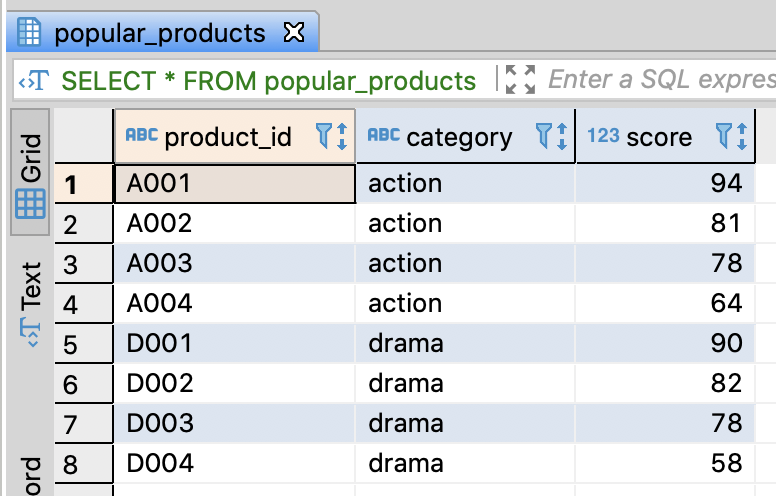
Ordering in a group
- You can order records through ORDER BY
- There are several functions to return a sequent order
| Function | Description |
|---|---|
| ROW_NUMBER | Returns a unique sequence number |
| RANK | Returns the rank number in a group and skips the number if there are same rank values eg. 1, 2, 2, 4, 5 |
| DENSE_RANK | Returns the rank number in a group and deosn’t skip the number if there are same rank values eg. 1, 2, 2, 3, 4 |
- And also, there are functions that return the previous or next record
| Function | Description |
|---|---|
| LAG(column_name) | Returns the previous record in a group |
| LAG(column_name, n) | Returns the previous Nth record in a group |
| LEAD(column_name) | Returns the next record in a group |
| LEAD(column_name, n) | Returns the next Nth record in a group |
-- Ordering in a table
SELECT product_id
, score
-- Unique rank by score
, ROW_NUMBER() OVER(ORDER BY score DESC) AS rownum
-- Skip duplicate rank
, RANK() OVER(ORDER BY score DESC) AS rank
-- Don't skip duplicate rank
, DENSE_RANK() OVER(ORDER BY score DESC) AS dense_rank
-- Previous record
, LAG(product_id) OVER(ORDER BY score DESC) AS lag1
-- Previous 2nd record
, LAG(product_id, 2) OVER(ORDER BY score DESC) AS lag2
-- Next record
, LEAD(product_id) OVER(ORDER BY score DESC) AS lead1
-- Next 2nd record
, LEAD(product_id, 2) OVER(ORDER BY score DESC) AS lead2
FROM popular_products
ORDER BY rownum
;
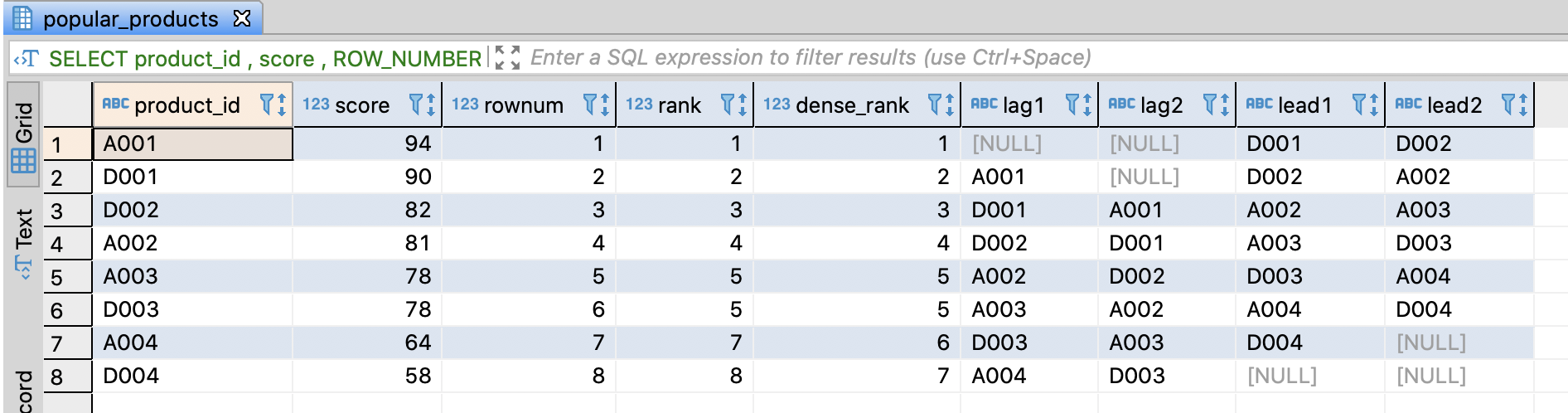
Combine ordering and intensive functions
- There are functions that return frst or last value in a window group like FIRST_VALUE, LAST_VALUE
- And you can set the range of a window
-- Combine ordering and intensive functions
SELECT product_id
, score
, ROW_NUMBER() OVER(ORDER BY score DESC)
AS rownum
-- Cumulative score from the score of a high rank to current in a window
, SUM(score)
OVER(ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS cum_score
-- Average score between previous record, current, and next record
, AVG(score)
OVER(ORDER BY score DESC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
AS local_avg
-- Product_id of top ranked record
, FIRST_VALUE(product_id)
OVER(ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
AS first_value
-- Product_id of bottom ranked record
, LAST_VALUE(product_id)
OVER(ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
AS first_value
FROM popular_products
ORDER BY rownum
;
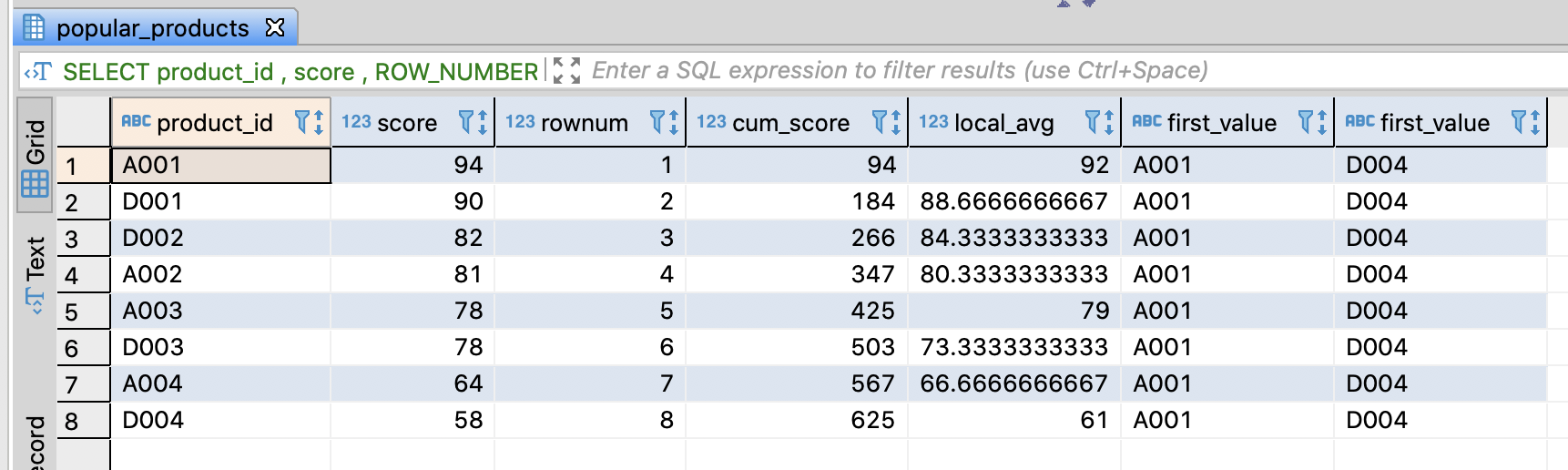
Define a window frame
- Define a relative frame based on current record
- ‘ROWS BETWEEN start AND end’ is the basic clause
- You can use CURRENT_ROW(current row), n PRECEDING(n previous row), n FOLLOWING(n next row), UNBOUNDED PROCEDING(all previous rows), UNBOUNDED FOLLOWING(all next rows) keyword in start or end
- If you don’t define a window frame, the ranges of default frame are whole rows without ORDER BY or from the first record to current record with ORDER BY
- PostgresSQL supports array_agg(column_name) keyword and Hive, SparkSQL support collect_list(column_name) for data-intensive
Redshift supports listagg such as array_agg and collect_list. However, it is unable to used with a window frame
-- Integrate product_id by window frames
SELECT product_id
, ROW_NUMBER() OVER(ORDER BY score DESC)
AS rownum
-- All records
, array_agg(product_id) -- collect_list(product_id)
OVER(ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
AS whole_agg
-- From the first record to current record
, array_agg(product_id)
OVER(ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS cum_agg
-- From previous record to next record
, array_agg(product_id)
OVER(ORDER BY score DESC
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
AS local_agg
FROM popular_products
WHERE category = 'action'
ORDER BY rownum
;
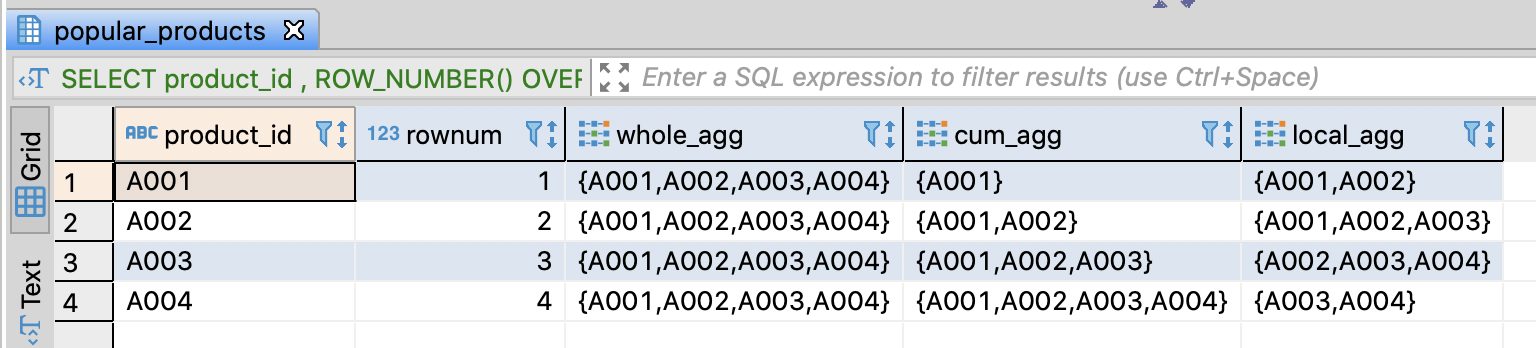
Combine PARTITION BY and ORDER BY
-- Combine PARTITION BY and ORDER BY
SELECT category
, product_id
, score
-- Unique rank by category
, ROW_NUMBER()
OVER(PARTITION BY category ORDER BY score DESC)
AS rownum
-- Rank with duplication by category
, RANK()
OVER(PARTITION BY category ORDER BY score DESC)
AS rank
-- Rank with duplication and skip duplicate rank
, DENSE_RANK()
OVER(PARTITION BY category ORDER BY score DESC)
AS dense_rank
FROM popular_products pp
ORDER BY category, rownum
;
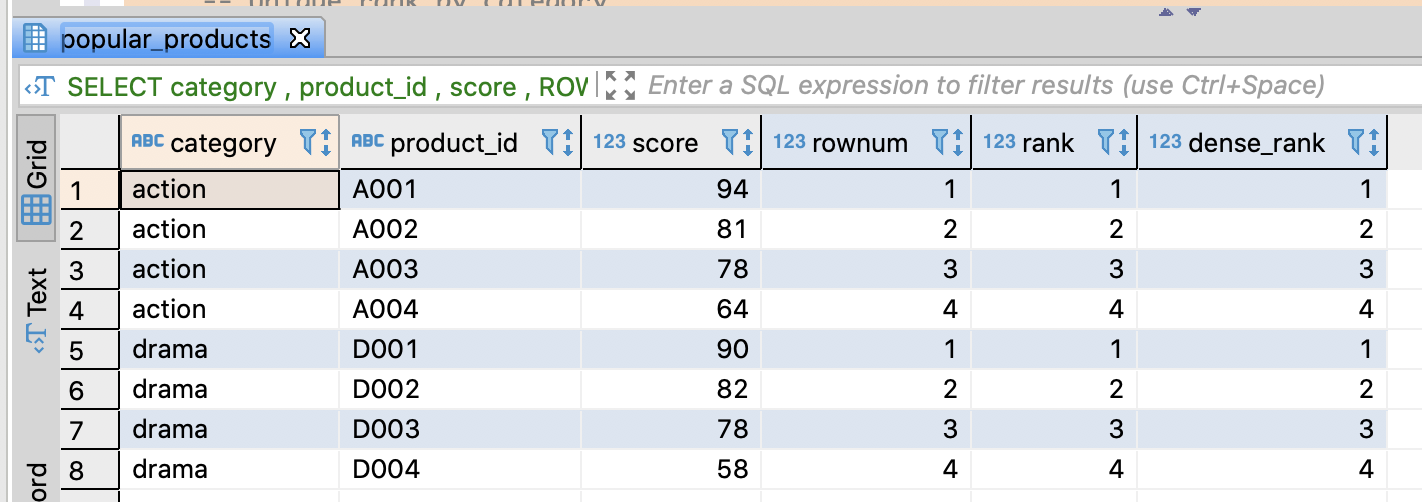
Extract top n by category
-- Extract top 2 products by category
SELECT *
FROM
(SELECT category
, product_id
, score
, ROW_NUMBER()
OVER(PARTITION BY category ORDER BY score DESC)
AS rank
FROM popular_products pp
) AS popular_products_with_rank
WHERE rank <= 2
ORDER BY category, rank
;
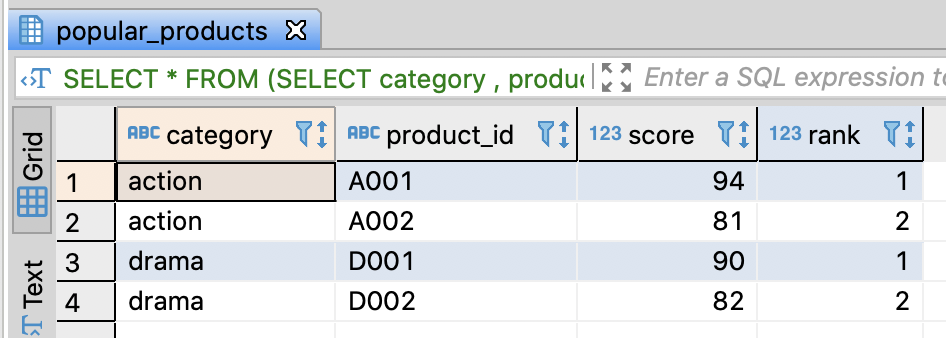
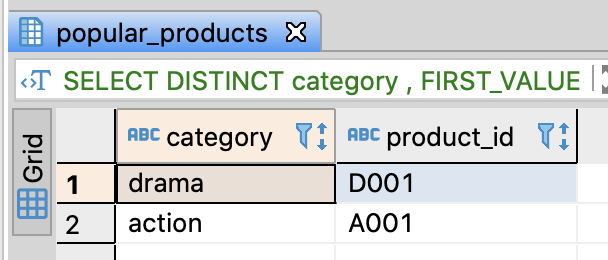
-- Extrat top ranked product by category
SELECT DISTINCT category
-- the top ranked product_id
, FIRST_VALUE(product_id)
OVER(PARTITION BY category ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
AS product_id
FROM popular_products pp
;
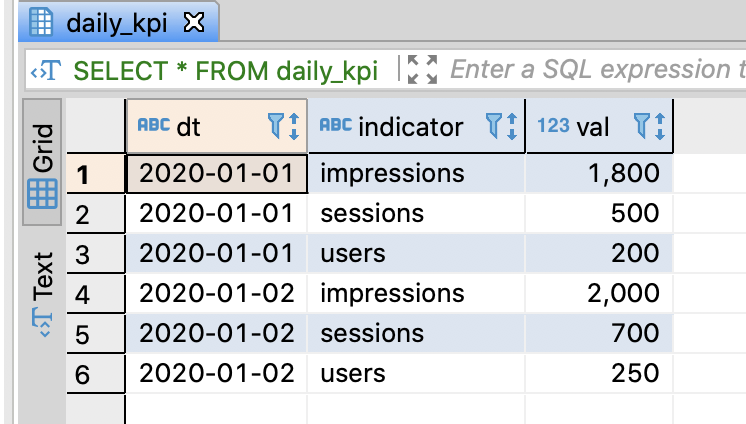
3.7.3. Convert columns into rows
Create table and insert sample data
-- DROP TABLE IF EXISTS daily_kpi;
-- Create KPI(Key Point Indicator) table
CREATE TABLE daily_kpi (
dt varchar(255)
, indicator varchar(255)
, val integer
);
-- Insert sample data
INSERT INTO daily_kpi
VALUES
('2020-01-01', 'impressions', 1800)
, ('2020-01-01', 'sessions' , 500)
, ('2020-01-01', 'users' , 200)
, ('2020-01-02', 'impressions', 2000)
, ('2020-01-02', 'sessions' , 700)
, ('2020-01-02', 'users' , 250)
;
commit;
-- Select sample data
SELECT *
FROM daily_kpi
;
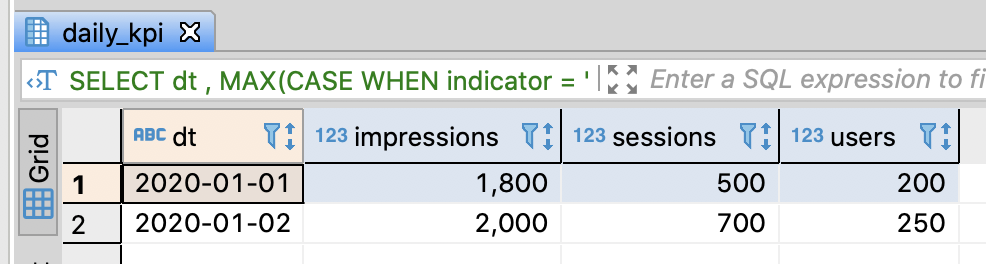
Convert rows into columns
- Use GROUP BY and MAX(CASE) because there are no duplicate indicators per dt
-- Convert rows into columns through GROUP_BY and MAX(CASE)
SELECT dt
, MAX(CASE WHEN indicator = 'impressions' THEN val END)
AS impressions
, MAX(CASE WHEN indicator = 'sessions' THEN val END)
AS sessions
, MAX(CASE WHEN indicator = 'users' THEN val END)
AS users
FROM daily_kpi
GROUP BY dt
ORDER BY dt
;
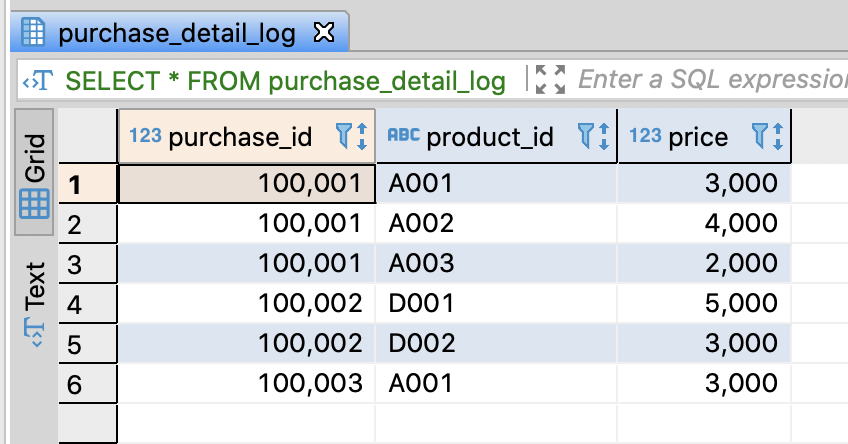
Create purchase log table and insert sampled data
-- DROP TABLE IF EXISTS purchase_detail_log;
-- Create purchase log table
CREATE TABLE purchase_detail_log (
purchase_id integer
, product_id varchar(255)
, price integer
);
-- Insert sample data
INSERT INTO purchase_detail_log
VALUES
(100001, 'A001', 3000)
, (100001, 'A002', 4000)
, (100001, 'A003', 2000)
, (100002, 'D001', 5000)
, (100002, 'D002', 3000)
, (100003, 'A001', 3000)
;
commit;
-- Select sample data
SELECT *
FROM purchase_detail_log
;
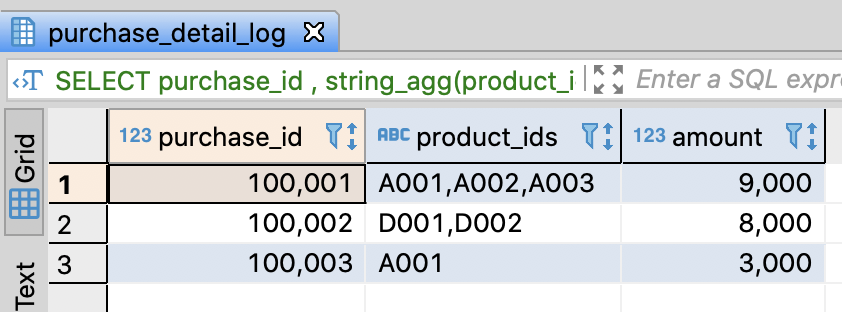
Convert rows into 1 row with comma delimiters
- PostgreSQL and BigQuery support string_agg(column_name, delimiter) and Redshift also supports listagg(column_name, delimiter) to integrate rows into 1 row with delimiters
- Hive and SparkSQL are available to integrate them through collect_list(column_name) and concat_ws(delimiter, array)
-- Convert rows into 1 row with comma delimiters
SELECT purchase_id
-- if PostgresSQL, BigQuery
, string_agg(product_id, ',') AS product_ids
-- if Redshift
-- , listagg(product_id, ',') AS product_ids
-- if Hive, SparkSQL
-- , concat_ws(',', collect_list(product_id)) AS product_ids
, SUM(price) AS amount
FROM purchase_detail_log
GROUP BY purchase_id
ORDER BY purchase_id
;
3.7.4. Convert rows into columns
- It is more complicate than converting columns into rows
- However, it is useful to analyze data and there are many cases which need it
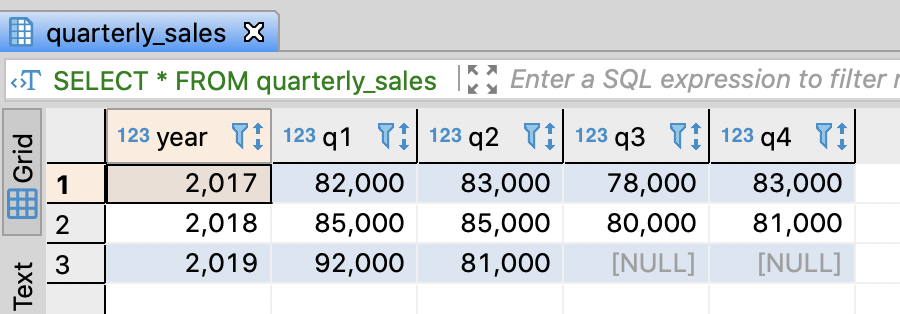
Quarterly sales table and insert sample data
- This table is already exits because I made it in Tutorial #3 - Manipulating multiple values / 3.6.2. Compare multiple values
- If you haven’t this table, execute the query below
-- DROP TABLE IF EXISTS quarterly_sales;
-- Create quarterly sales table
CREATE TABLE quarterly_sales (
year integer
, q1 integer
, q2 integer
, q3 integer
, q4 integer
);
-- Insert sample data
INSERT INTO quarterly_sales
VALUES
(2017, 82000, 83000, 78000, 83000)
, (2018, 85000, 85000, 80000, 81000)
, (2019, 92000, 81000, NULL , NULL )
;
commit;
-- Select sample data
SELECT *
FROM quarterly_sales
;
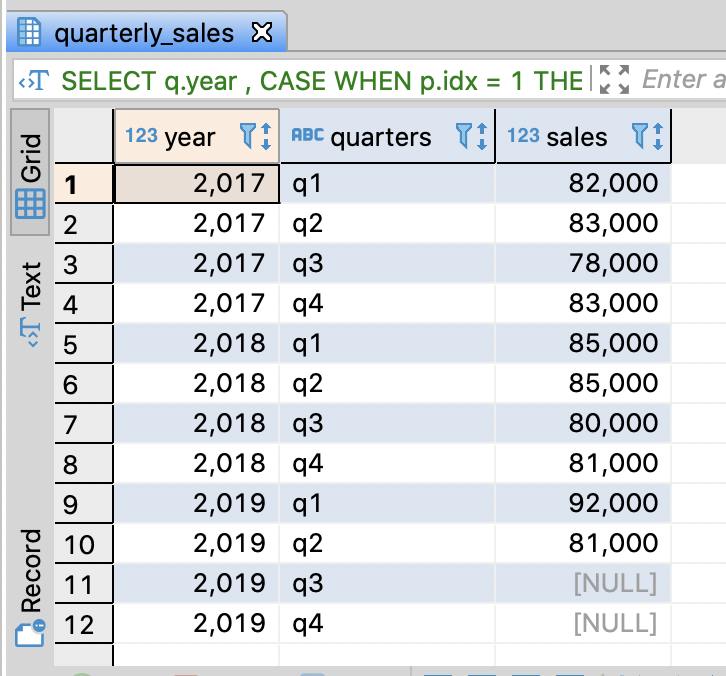
Convert rows into columns
- You have to make pivot table and do CROSS JOIN with it
-- CROSS JOIN with a pivot table
SELECT q.year
-- Print labels from Q1 to Q4
, CASE WHEN p.idx = 1 THEN 'q1'
WHEN p.idx = 2 THEN 'q2'
WHEN p.idx = 3 THEN 'q3'
WHEN p.idx = 4 THEN 'q4'
END AS quarters
-- Print sales from Q1 to Q4
, CASE WHEN p.idx = 1 THEN q.q1
WHEN p.idx = 2 THEN q.q2
WHEN p.idx = 3 THEN q.q3
WHEN p.idx = 4 THEN q.q4
END AS sales
FROM quarterly_sales AS q
CROSS JOIN
-- Create sequence table followed columns in quaterly_sales
(SELECT 1 AS idx
UNION ALL
SELECT 2 AS idx
UNION ALL
SELECT 3 AS idx
UNION ALL
SELECT 4 AS idx
) AS p
;
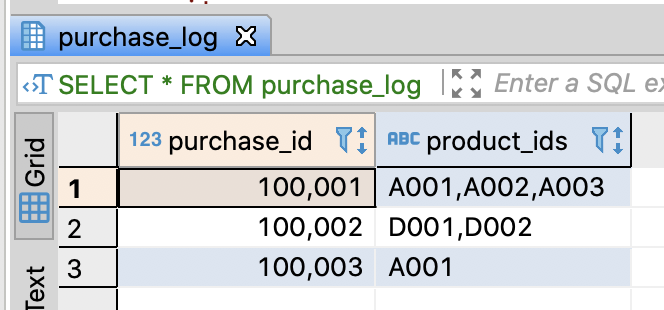
Create purchase log table and insert sample data
-- DROP TABLE IF EXISTS purchase_log;
-- Create purchase_log
CREATE TABLE purchase_log (
purchase_id integer
, product_ids varchar(255)
);
-- Insert sample data
INSERT INTO purchase_log
VALUES
(100001, 'A001,A002,A003')
, (100002, 'D001,D002')
, (100003, 'A001')
;
commit;
-- Select sample data
SELECT *
FROM purchase_log
;
Convert array into rows
- Several middlewares support TABLE_FUNCTION whichi returns a table
- For example, PostgreSQL and BigQuery have unnest(array) function and Hive and SparkSQL have explode(array) function and they convert an array into a table
-- Convert an array into a table
-- if PostgreSQL
SELECT unnest(ARRAY['A001', 'A002', 'A003']) AS product_id;
-- if BigQuery
-- SELECT * FROM unnest(ARRAY['A001', 'A002', 'A003']) AS product_id;
-- if Hive, SparkSQL
-- SELECT explode(ARRAY['A001', 'A002', 'A003']) AS product_id;
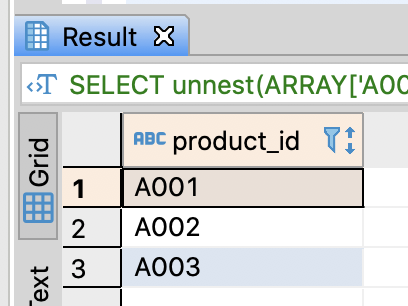
- You have to use CROSS JOIN in PostgreSQL or BigQuery and use LATERAL VIEW in Hive or SparkSQL
-- Convert a stirng with delimiters into a table
SELECT purchase_id
, product_id
FROM purchase_log AS p
-- if PostgreSQL
CROSS JOIN unnest(pg_catalog.string_to_array(product_ids, ',')) AS product_id
-- if BigQuery
-- CROSS JOIN unnest(split(product_ids, ',')) AS prouct_id
-- if Hive, SparkSQL
-- LATERAL VIEW explode(split(producT_ids, ',') e AS producT_id
;
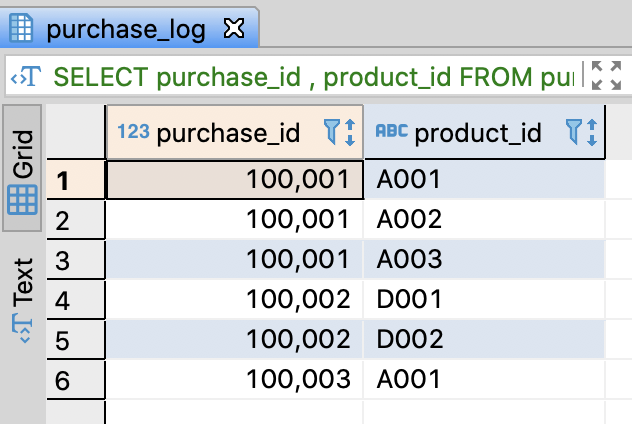
- You can use scalar value and a table function in the same time in PostgreSQL
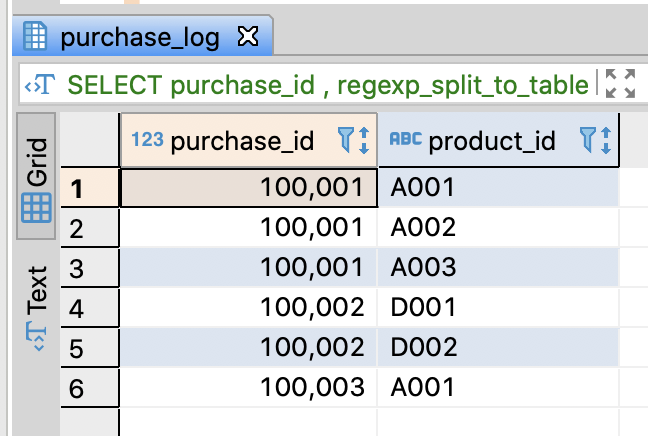
- PostgreSQL supports regexp_split_to_table() which returns a table from an string by the regualar expression
-- Convert a stirng with delimiters into a table withtout cross join
SELECT purchase_id
, regexp_split_to_table(product_ids, ',') AS product_id
FROM purchase_log
;
Convert a string into rows in Redshift
- Redshift doesn’t support array data type offically
- Therefore, it is more complicate for you to do it in Redshift and you have to do several pre processing
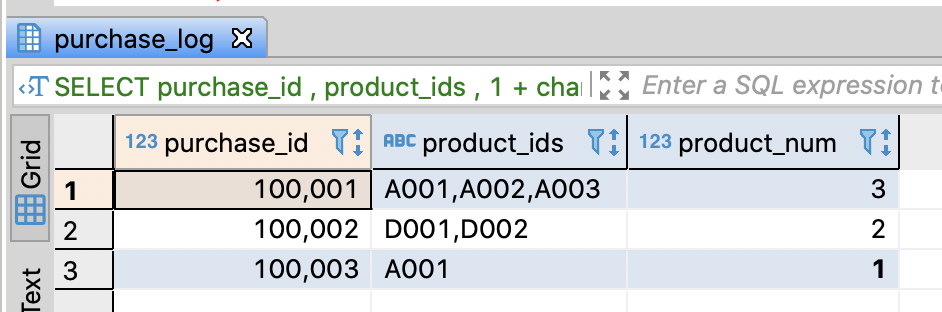
-- Calculate the count of products through the count of delimiters in Redshift
SELECT purchase_id
, product_ids
-- Remove comman by product_id
-- and calculate the count of products through the count of delimiters
, 1 + char_length(product_ids) - char_length(replace(product_ids, ',', ''))
AS product_num
FROM purchase_log
;
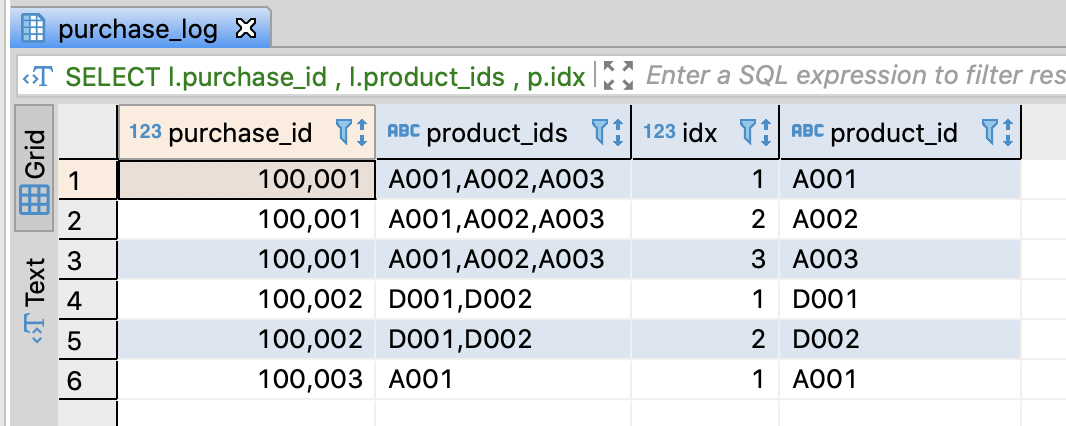
-- Convert a string into rows using a pivot table in Redshift
SELECT l.purchase_id
, l.product_ids
-- Set a sequence by the count of products
, p.idx
, split_part(l.product_ids, ',', p.idx) AS product_id
FROM purchase_log AS l
JOIN
(SELECT 1 AS idx
UNION ALL
SELECT 2 AS idx
UNION ALL
SELECT 3 AS idx
) AS p
-- Join when id of the pivot table is less than the count of products
ON p.idx <= (1 + char_length(product_ids) - char_length(replace(product_ids, ',', '')))
;
References
- 데이터 분석을 위한 SQL 레시피 - 한빛미디어
- SQL:2003 Wiki
댓글남기기